
Before the Zen-based Ryzen CPUs landed in 2017, AMD was in a very precarious situation, nearly on the verge of bankruptcy. The older “Bulldozer” FX CPUs were slow, inefficient, and overall an architectural disaster. In fact, Ryzen wouldn’t have had the impact it did if not for Bulldozer. Let’s have a look a the differences between the Ryzen and FX “Bulldozer” processors.

History of AMD CPUs: Bulldozer and the FX Lineup
After the third-gen K10 architecture, AMD due to a lack of funds decided to invest in a narrow, low-IPC, high-clock speed design. Basically, they tried making a CPU architecture with relatively lower single-threaded performance, and a lot of threads. They hoped to offset the former using higher clock speeds and hoped that applications would become increasingly multithreaded.
That, of course, didn’t happen, and the result was the disaster known as the Bulldozer architecture that gave birth to the FX processors. To make this design viable, AMD’s engineers had to increase the core counts as well as clock speeds. This led to a power-hungry CPU architecture that ran hot and didn’t perform anywhere as well as the competing Intel Core chips.
To get a clearer picture of how disadvantaged AMD’s Bulldozer CPUs were, here’s an example: To offer performance in line with the older Phenom II processors, FX needed to have a 40% higher operating speed (on average).
Higher clock speeds require an increased power draw which directly results in higher thermals and throttling. This made the FX processors and the Bulldozer architecture in general, unsuitable for laptops and notebook devices, while core counts higher than 8 were infeasible even for desktop parts.
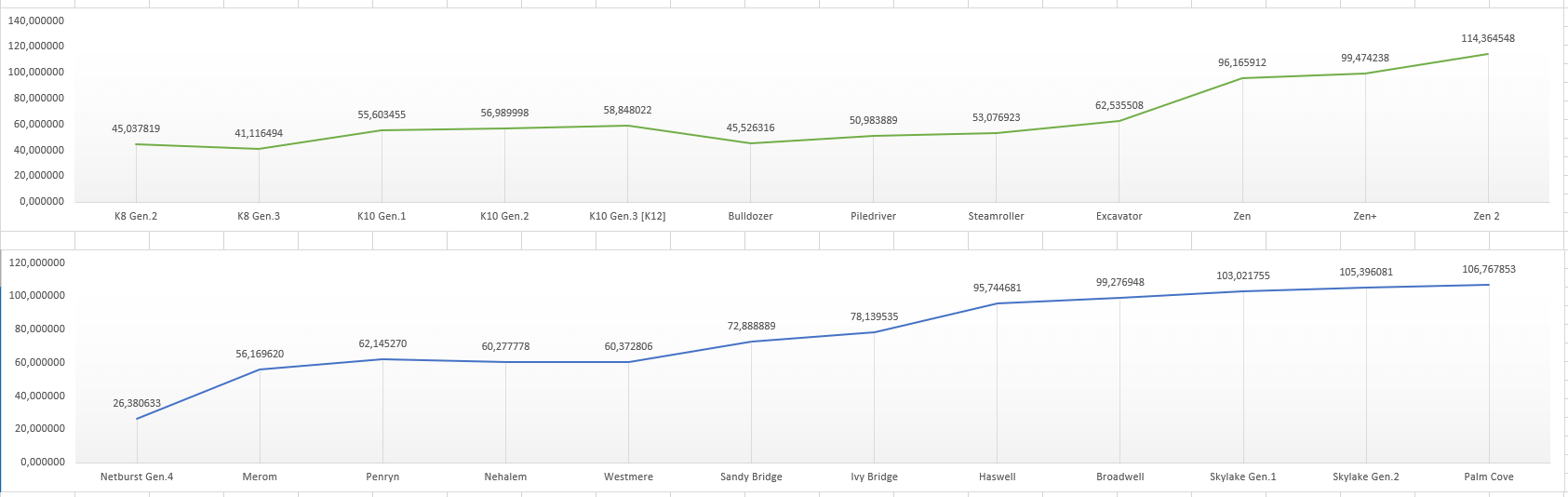
As you can see in the chart above, the IPC actually fell with the first generation of Bulldozer processors. It took three upgrade cycles to bring it back on par with K10. The company started to move in the right direction with Steamroller and Excavator but hit a roadblock soon after. The design limitations of the Bulldozer architecture prevented AMD’s design team from making further improvements without overhauling the layout. This marked the end of Bulldozer and its derivatives.
Then came the Zen microarchitecture with an aim to rectify the shortcomings of the Bulldozer design, and here we are today, with the Ryzen 5000 lineup based on the 7nm Zen 3 core.
AMD FX vs Ryzen CPUs: Comparing the Bulldozer and Zen Core
Let’s put the two architectures side-by-side and analyze the core difference between the Bulldozer and Zen core. In short, the former had so many bottlenecks it was impossible to make a sound chip without overhauling the entire design. Some of the main limitations were:
- Poor floating-point capabilities
- Shared logic (between two “cores”)
- Higher cache latency and size
- Narrower front-end
- Windows 7 scheduler
Poor Floating Point Capabilities
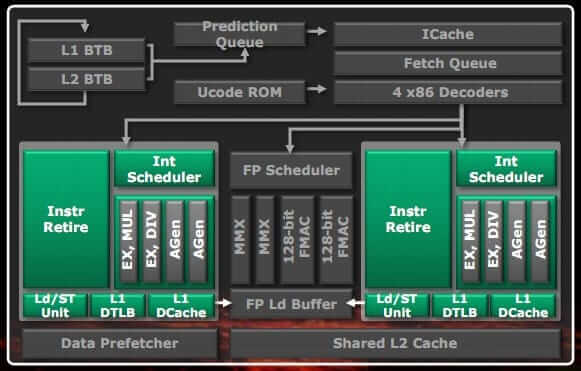
Right off the bat, one of the most disastrous design choices of Bulldozer was the shared logic scheme. There was only one floating-point unit (and scheduler) shared between two supposed cores. On top of that, this FPU couldn’t execute AVX256 (AVX-2) instructions without breaking them into two 128-bit segments. Intel’s Sandy Bridge had a rather robust AVX256 execution model, capable of performing 256-bit multiply + 256-bit add each cycle (per core). AMD’s Bulldozer, on the other hand, had two 128-bit fused multiply-accumulate (FMAC) units shared between two cores. Rather sad, isn’t it?
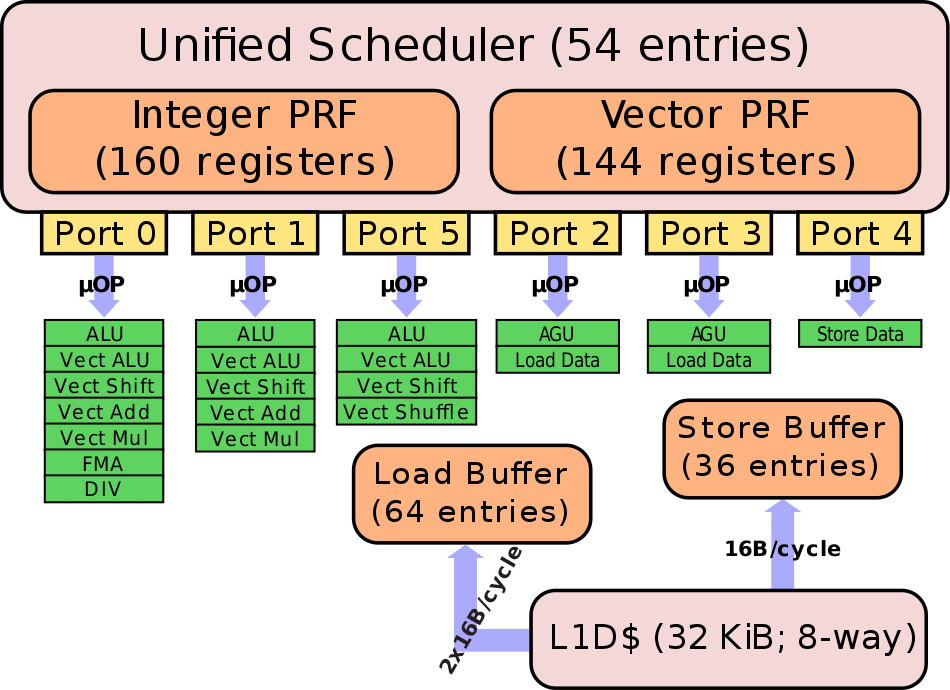
Sandy Bridge has three ports for executing micro-ops. Each has three EUs for executing data of three different types, namely INT, SIMD INT, and FP. The INT stack is 64-bit wide and handles GPIOs (General-purpose Integer Operations) while the SIMD INT and FP stacks are 128-bit wide. To perform 256-bit AVX operations, the Execution Engine uses the Integer SIMD Unit for the lower 128-bit half and the FP Unit for the upper 128-bit. In this way, Sandy Bridge can perform one 256-bit MUL along with one 256-bit ADD per cycle.
Shared Logic (Between two cores)
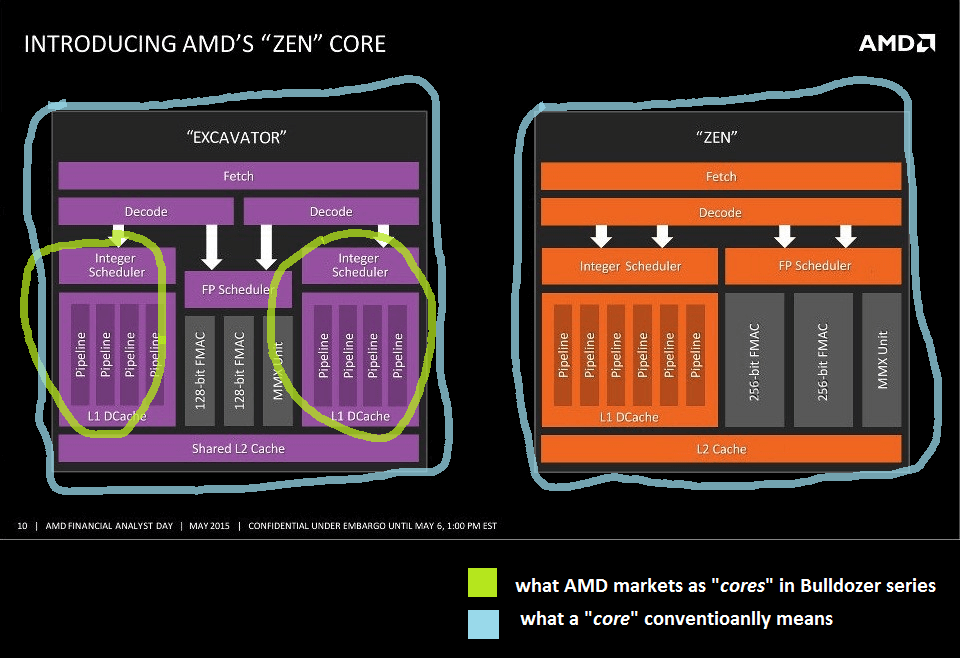
The shared front-end design not only doomed Bulldozer’s floating-point capabilities but the integer compute was also compromised.
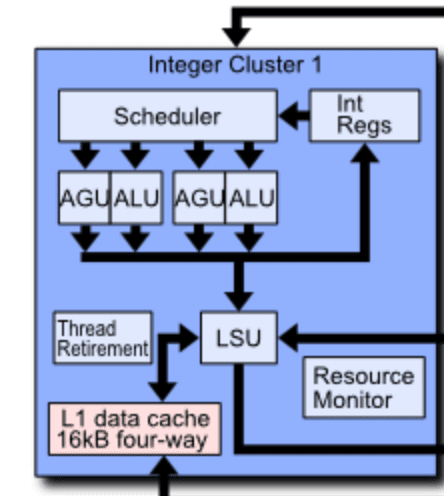
As you can see, where Zen can execute four integer micro-ops (plus two address generation), a Bulldozer cluster could only execute half as many. Moreover, it lacks the complexity of the Zen scheduler which can have as many as 56 integer instruction queues and 28 address generation queues.
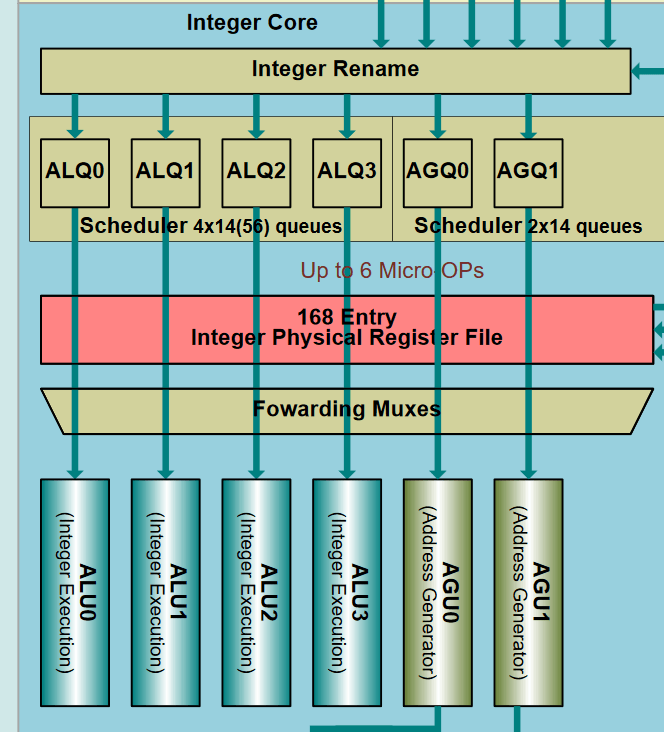
Higher Cache Latency and Size
Continued on the next page…
Not only did the Bulldozer architecture have a shared L2 cache between every two cores in a module, but it was also slower than the preceding K10 chips. The L2 on the AMD FX-8150 had a latency penalty of more than twice as much compared to Intel’s competing Sandy Bridge Core i7 (lesser is better).
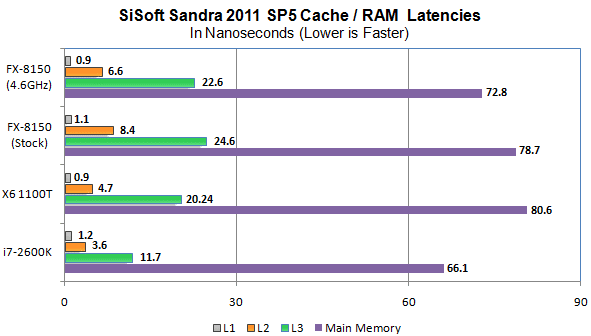
Although the caches on Bulldozer are larger than the ones on Sandy Bridge and Zen, they are considerably slower. Even at 4.6GHz, the FX chip’s L2 cache is 2x slower compared to the 2600K. The shared logic and cache architecture forced AMD to use a larger L2 cache, but the company went with cheaper and slower memory. Cache memory is one of the most expensive components of a CPU and considering how the Bulldozer parts perform, the company couldn’t afford to spend money on a faster, pricier cache reserve.
Narrower Front-End
Bulldozer’s front-end was another bottleneck. The same 4-way fetch and decode were shared between two cores. AMD utilized interleaved multi-threading to track individual threads and give priority to the one that needs most of the work completed. One thread could be worked upon per cycle, meaning that the other sat idle.
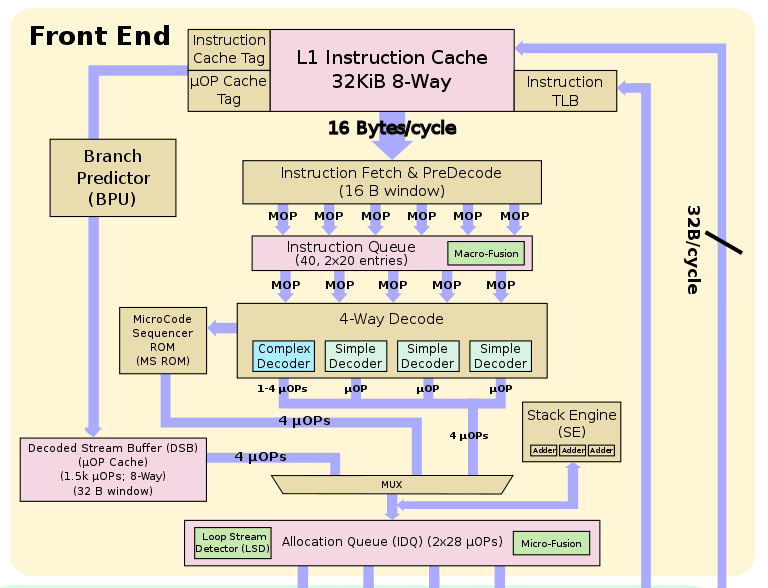
Intel’s Sandy Bridge and the new Zen architecture like a standard design have a dedicated front-end for each core. The former fetches six macro-ops per cycle, sending five to the 4-way decoder.
AMD’s Zen architecture also has a four-way decoder, but it can also fetch up to eight instructions from the op-cache. Bulldozer doesn’t even have a micro-op cache.
Windows 7 Scheduler
While all the other bottlenecks are relatively well-known, this last one is often overlooked. Back in the days of Bulldozer, Windows 7 was the de-facto Windows OS. The resource allocation and scheduling of the operating system weren’t suited for the Bulldozer architecture. AMD’s octa-core models were basically four modules consisting of two cores each, sharing resources. However, Windows 8 didn’t see it that way. It saw 8 independent cores running simultaneously.

When the scheduler assigned a new thread 1b (dependent on data from 1a) to a separate module, it created a problem. AMD’s Turbo Boost technology couldn’t be enabled in this scenario. And Windows 7 did this quite often. Considering that the Bulldozer architecture was built for higher clock speeds to offset the low IPC, this was a major drawback.
AMD’s Turbo Core kicks in only when four cores from two modules are active. However, there are many times when the above-explained situation will cause four cores from three modules to be leveraged. Turbo Boost can’t be enabled in this scenario. Tests show that disabling two modules actually yields better performance than stock in many applications.
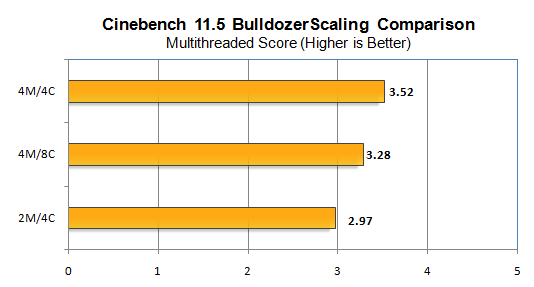
This is due to the poor IPC and single-threaded performance of the Bulldozer FX processors. Here are the complete diagrams of the Bulldozer, Sandy Bridge, Sky Lake, and Zen architectures to compare side-by-side:
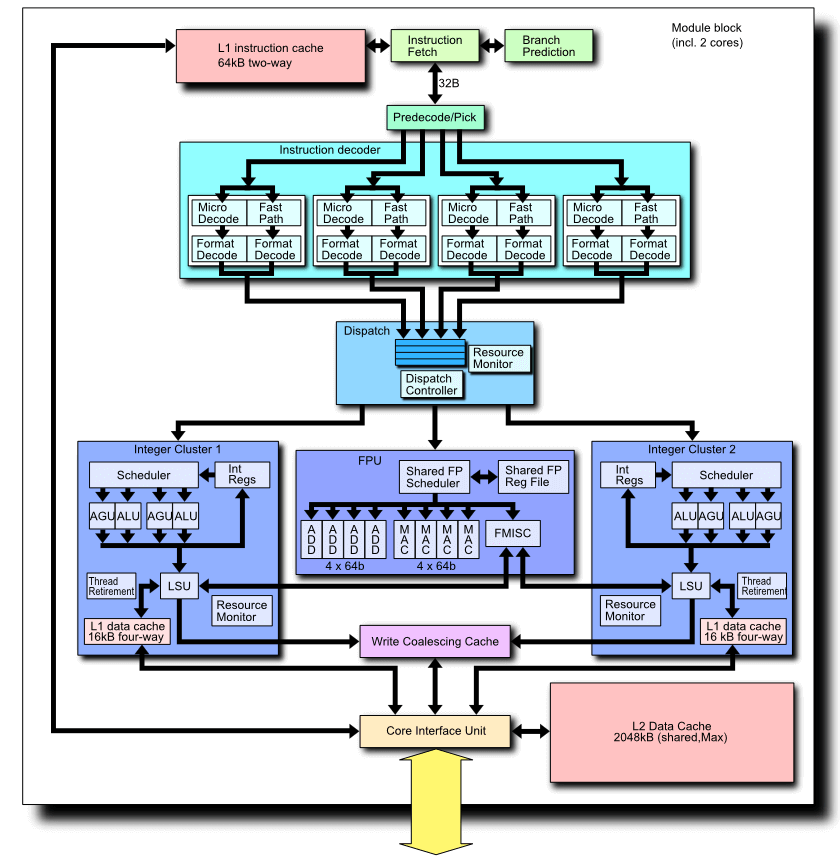
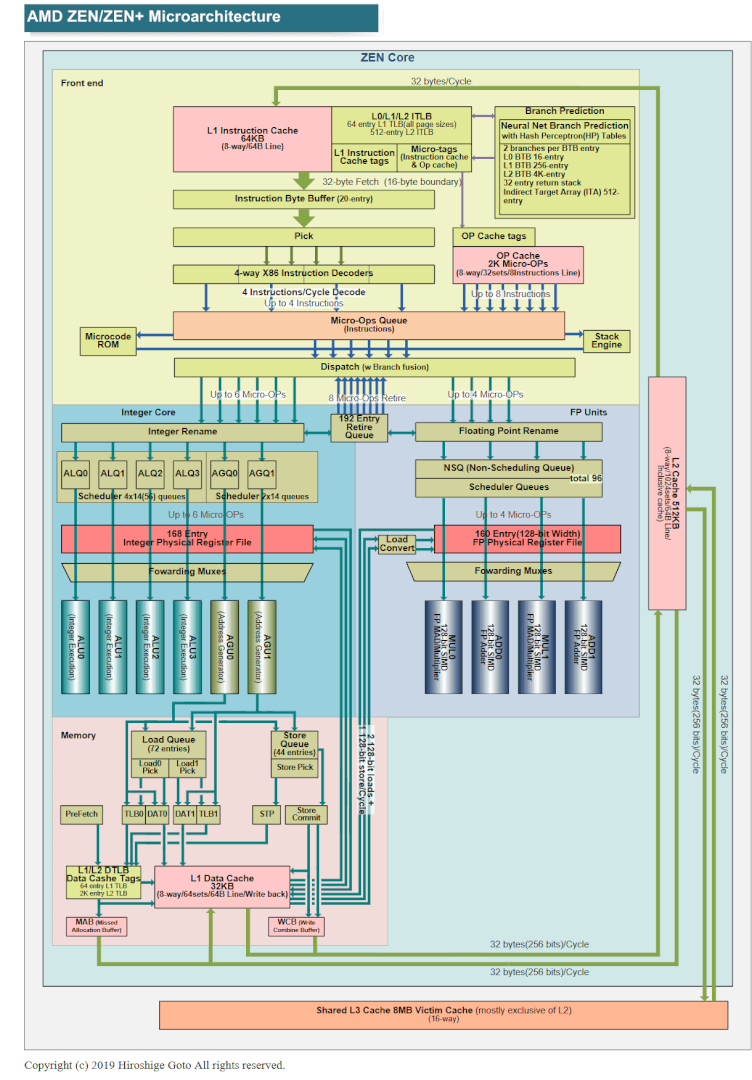
Sources: Wikichip, AMD, Intel and PC Watch Japan.
-
 Intel Core i9-13900K Performance Drop with Baseline Profile on B760 Boards Explored
Intel Core i9-13900K Performance Drop with Baseline Profile on B760 Boards Explored
-
 Intel 15th Gen Core i5-15400F (Core Ultra 5 240F) Specs Leak Out: 20A Chips in 2025?
Intel 15th Gen Core i5-15400F (Core Ultra 5 240F) Specs Leak Out: 20A Chips in 2025?
-
 13th Gen i9-13900K is ~30% Slower at Intel Spec than Board Partner “Optimized” Power Limits
13th Gen i9-13900K is ~30% Slower at Intel Spec than Board Partner “Optimized” Power Limits
-
 AMD Ryzen 9000 “Strix Point” CPU: Nearly As Fast as Intel’s Core Ultra “Meteor Lake” at 1.4 GHz
AMD Ryzen 9000 “Strix Point” CPU: Nearly As Fast as Intel’s Core Ultra “Meteor Lake” at 1.4 GHz