Modern processor architectures utilize various execution models. Out of these, two are most popular: SIMD (Single Instruction Multiple Data) and SIMT (Single Instruction Multiple Threads). There’s also SMT (Simultaneous Multithreading), but that’s something else we’ll be checking at the end. In this post, we have a look at the SIMD and SIMT processor execution modes and see how they differ from one another.


SIMD: Single Instruction Multiple Data
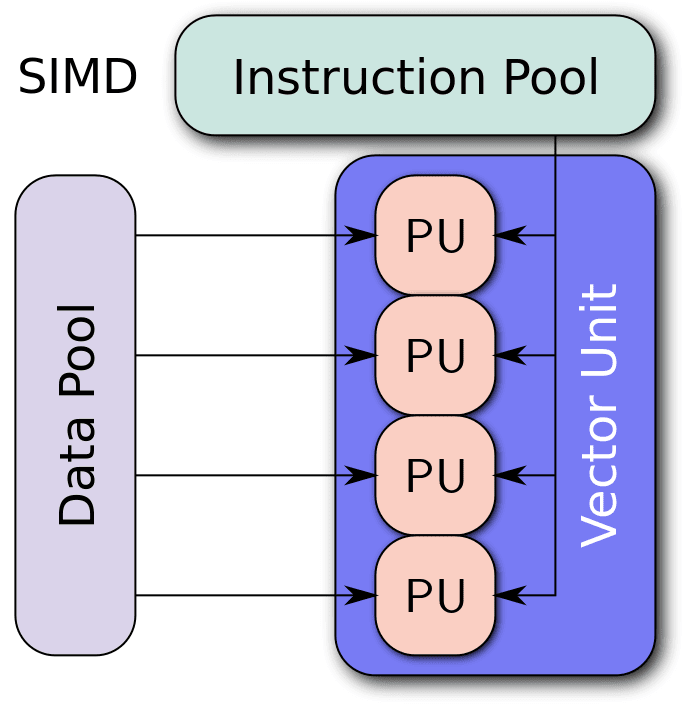
Right off the bat, what is SIMD, and more importantly how does it work? SIMD is an execution model, meaning it’s method employed by processors to queue similar data sets in the pipeline and execute them in parallel. It’s one of the most popular EMs used by modern CPUs and GPUs. Single Instruction Multiple Data. As the name suggests, it works by employing a single instruction on multiple data sets simultaneously.
What that means is: One particular instruction is executed by multiple Execution units on multiple data sets. The EUs may be ALUs (Arithmetic Logic Units) or FPUs (Floating Point Units), but the key point here is that they all receive the same instruction from a shared Control Unit and then execute it on multiple different data sets.

This improves data-level parallelism (not instruction level or concurrency) by letting the CPU perform identical tasks on different operands. In the above example, you can see that the lines of code include many functions that require the same operator. In the first column, all four lines basically involve the addition to two different matrices. SIMD allows all four to be executed in the same clock cycle. One important thing to note here is that SIMD uses execution units, not threads or cores.
SIMT: Single Instruction Multiple Threads
SIMT is the thread equivalent of SIMD. While the latter uses Execution Units or Vector Units, SIMT expands it to leverage threads. In SIMT, multiple threads perform the same instruction on different data sets. The main advantage of SIMT is that it reduces the latency that comes with instruction prefetching.
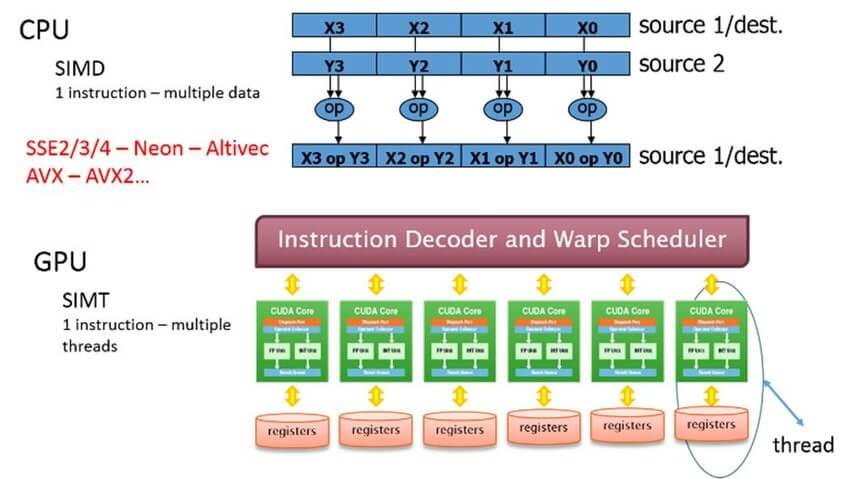
SIMT is generally used in Super-scalar processors to implement SIMD. So technically, each core is scalar in nature but it still works similarly to an SIMD model by leveraging multiple threads to do the same task on various data sets.
Every time the GPU needs to execute a particular instruction, the data and instructions are fetched from the memory and then decoded and executed. In this case, all the data sets (up to a certain limit) that need the same instruction for execution are prefetched and executed simultaneously using the various threads available to the processor.
SMT: Simultaneous Multi-Threading
SMT or Simultaneous Multithreading allows a CPU core to leverage multiple threads at a time. Although theoretically, you can have up to 8 threads per core via SMT, it’s only feasible to have two. SMT is analogous to having two cargo belts at the airport luggage sorting, and one person sorting them.
There will be times when one belt is empty but the other still has pending work. In this instance, the person will switch to the other belt and continue sorting till the first belt gets more luggage. This is similar to how SMT operates in CPUs. There are times when there’s a memory delay or a cache miss, at this time, the CPU core would normally stay idle. SMT aims to take advantage of this to fully saturate the CPU time.
The CPU core architecture needs to be modified internally to support SMT. This usually involves increasing the register size (and in some cases the cache size as well) to allow the distribution of resources among the two threads equally, as well as to prevent contention.
Although modern CPUs leverage SMT quite well, there are still times when it’s redundant. That is mostly in latency intensive tasks where there is little to no delay in the pipeline. SMT can even hamper performance in applications that are resource intensive (register and cache). Here the two threads are forced to compete against one another for resources, leading to reduced performance.


