
Intel’s adoption of the hybrid core architecture has significantly changed the roadmap of the PC chipmaking industry. More and more applications are now taking advantage of the “secondary” low-power E-cores to boost performance and efficiency. This approach has its shortcomings, which Intel plans to iron out in the coming years. The first, most radical change involves replacing hyper-threading with a more efficient pseudo-multi-threaded solution: Rentable Units.
As far as the different applications running on your PC are concerned, they can’t differentiate between the physical and logical cores born out of hyper-threading. They see all as equal. On the hardware side, enabling hyper-threading requires additional registers on each core to keep track of the data associated with the logical thread. The program counter is one such register.


An 8-core CPU with hyper-threading will still have only eight executing threads at any particular instance. The reason being that the cache (L1 and L2) and the Execution Units (ALUs) on each core can only work on one thread at a time. So, then what does hyper-threading, also Simultaneous Multi-Threading, do on a CPU?
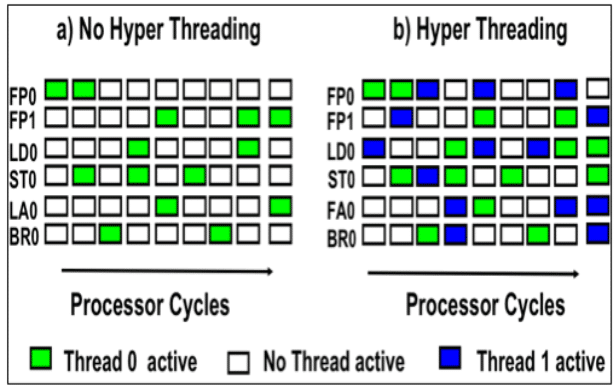
Hyper-threading ensures that the CPU cores (mostly the Execution Units) don’t slack off. In the above figure, you can see the difference in core utilization with and without hyper-threading. The logical or hyper-thread takes over when the primary thread is stalled or waiting for an input, utilizing the otherwise wasted CPU time, also known as bubbles.
Hyper-threading is often compared to a dock worker collecting baggage from two conveyor belts simultaneously. He can be more efficient if the intervals between two baggage units on a belt are filled by the units coming from a second belt. Of course, this doesn’t always work as planned. Not all workloads have the stalls needed to make hyper-threading relevant, in which case the two threads start competing for resources, lowering the performance.
An Intel patent is the first to officially hint at the coming of the reapers, err, I mean the Rentable Units. The patent calls the RU the “Instruction Processing Circuit“, which indicates that it may be called something else at release. In the below figure, you can see the difference between hyper-threading and Rentable Units and how it’s especially useful on hybrid-core processors.
On a hybrid-core CPU, the more demanding task is assigned to the P-core, leaving the others to the E-core. Being considerably faster, the former often ends up finishing the task much earlier than its counterpart, leaving the core idle for a notable period (bubble).
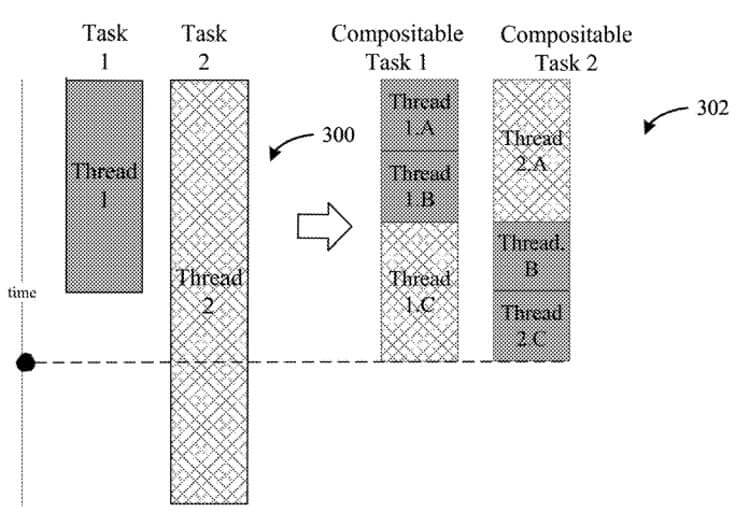
The Rentable Unit splits the first thread of incoming instructions into two partitions, assigning two different cores to each based on the complexity. In the above example, we’ve got two threads (1 and 2). The scheduler divides each into three partitions (A, B, C).
The first two partitions of 1 (1A, 1B) are executed on the P-core, while the third (1C) is handed to the E-core. Similarly, the first partition of thread 2 (2A) is processed by the E-core, while the other two (2B, 2C) are executed by the P-core. (The densely shaded sections are P, while the lightly shaded ones represent E-cores)
This approach is much more flexible than hyper-threading. Without going into too much detail, Rentable Units will employ various timers and counters to track the utilization of each P and E core, passing the next thread of instructions to whichever is idle and most suited to the task.
Different paths will be weighted for the most optimal outcome, that is, which core is best suited for the task given current resource usage and partition complexity.
This implementation will come with its own challenges. For example, keeping track of the various thread buffers will require a fair amount of registers/cache. That said, this method looks much cleaner and more efficient than existing hyper-threading designs.
Via: ElChapuzas.


