
- DDR5 also increases the memory density all the way (up) to 64Gb from 16Gb and both the VDD and VPP voltages have gone down from 1.2v to 1.1v to reduce the power draw.
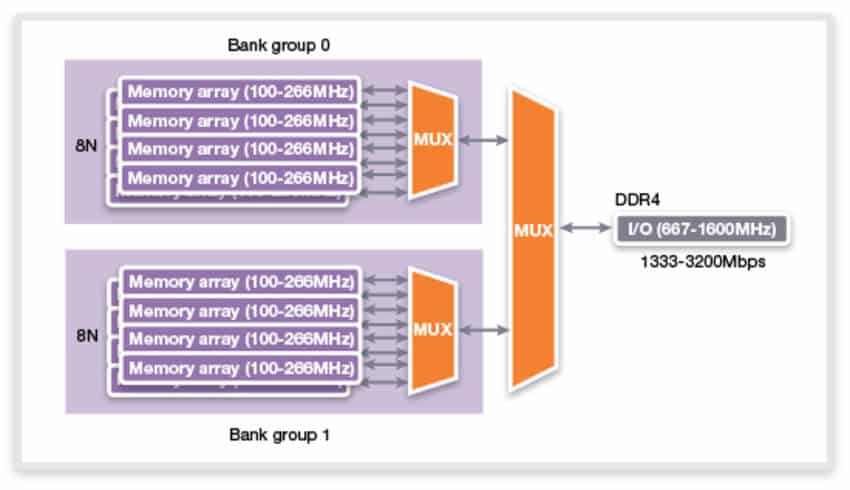
To understand what burst length means, you need to know how memory is accessed. When the CPU or cache requests new data, the address is sent to the memory module and the required row, after which the column is located (if not present, a new row is loaded). Keep in mind that there’s a delay after every step. Then the entire column is sent across the memory bus, in bursts. For DDR4 and GDDR5, each burst was 8 (or 16B). With DDR5 (and GDDR5X/6), it has been increased to as much as 32 (up to 64B). There are two bursts per clock and they happen at the effective data rate.



GDDR6, like GDDR5X, has a 16n (BL16) prefetch but it’s divided into two channels. Therefore, GDDR6 fetches 32 bytes per channel for a total of 64 bytes just like GDDR5X and twice that of GDDR5. While this doesn’t improve memory transfer speeds over GDDR5X, it allows for more versatility. The burst length is also the same as GDDR5X at 16 (64B).
GDDR6 can fetch the same amount of data as GDDR5X but across two separate channels, allowing it to function like two smaller chips instead of one, in addition to a wider single one. Other than that, GDDR6 also increases the density to 16Gb (2x compared to GDDR5X, with a JEDEC max of 32Gb) and significantly improves bandwidth by increasing the base clock from 12Gbps to up to 14Gbps (16Gbps max).
DDR4/DDR5/GDDR5= DDR; GDDR5X/GDDR6= QDR
DDR3, DDR4, GDDR5, and the newer DDR5 standards use a double data rate or DDR data transmission scheme. This means that bits (equal to BL) are transferred at the rising and falling edge of the word clock (WCK). With GDDR5X, graphics memory moved to a quad-rate mode
Therefore, data bits toggle four times per cycle (twice as fast as DDR) or four times faster than the word clock (WCK). Both GDDR5X and GDDR6 can be run in both DDR or QDR modes. However, when running the former in DDR, the effective speed drops to half as much. With GDDR6, you can use both DDR and QDR modes at full speeds of up to 14 Gbps. For example, a GDDR6 module running at 14Gbps, the WCK will run at 7GHz for a DDR device, and at 3.5 for a QDR device. In both cases, CK, the command and address clock, will run at 1.75GHz, with command and address lines themselves running at 1.75Gbps.
GDDR6 vs GDDR6X
NVIDIA is the first vendor to opt for GDDR6X memory in its RTX 30 series GPUs, at least the higher-end ones. It increases the per-pin bandwidth from 14Gbps to 21Gbps and the overall bandwidth to 1008GB/s, even more than a 3072-bit wide HBM2 stack.
| GDDR6X | GDDR6 | GDDR5X | HBM2 | |
| B/W Per Pin | 21 Gbps | 14 Gbps | 11.4 Gbps | 1.7 Gbps |
| Chip capacity | 1 GB (8 Gb) | 1 GB (8 Gb) | 1 GB (8 Gb) | 4 GB (32 Gb) |
| No. Chips/KGSDs | 12 | 12 | 12 | 3 |
| B/W Per Chip/Stack | 84 GB/s | 56 GB/s | 45.6 GB/s | 217.6 GB/s |
| Bus Width | 384-bit | 384-bit | 352-bit | 3072-bit |
| Total B/W | 1008 GB/s | 672 GB/s | 548 GB/s | 652.8 GB/s |
| DRAM Voltage | 1.35 V | 1.35 V | 1.35 V | 1.2 V |
| Data Rate | QDR | QDR | DDR | DDR |
| Signaling | PAM4 | Binary | Binary | Binary |
The secret sauce behind GDDR6X memory is PAM4 encoding. In simple words, it doubles the data transfer per clock compared to GDDR6 which uses NRZ or binary coding.
With NRZ, you had just two states, 0 and 1. PAM4 doubles it to four, 00, 01,10, and 11. Using these four states, you can send four bits of data per cycle (two per edge). The drawback with PAM4 is the high price especially at the higher frequencies of GDD6X. This is the reason why no one has tried to implement it in consumer memory before.
This is one downside with this. While GDDR6 has a burst length of 16 bytes (BL16), GDDR6X is limited to BL8 or 8 bytes, but because of PAM4 signaling, each of its 16-bit channels will also deliver 32 bytes per operation. Therefore, most of the improvement in bandwidth has come from higher operating frequency on GDDR6X. Keep in mind that GDDR6X is not a JEDEC standard, rather a proprietary solution from Micron.
High Bandwidth Memory (HBM)
First popularized by AMD’s Fiji graphics cards, high bandwidth memory or HBM is a low power memory standard with a wide bus. HBM achieves substantially higher bandwidth compared to GDDR5 while drawing much lesser power in a small form factor.
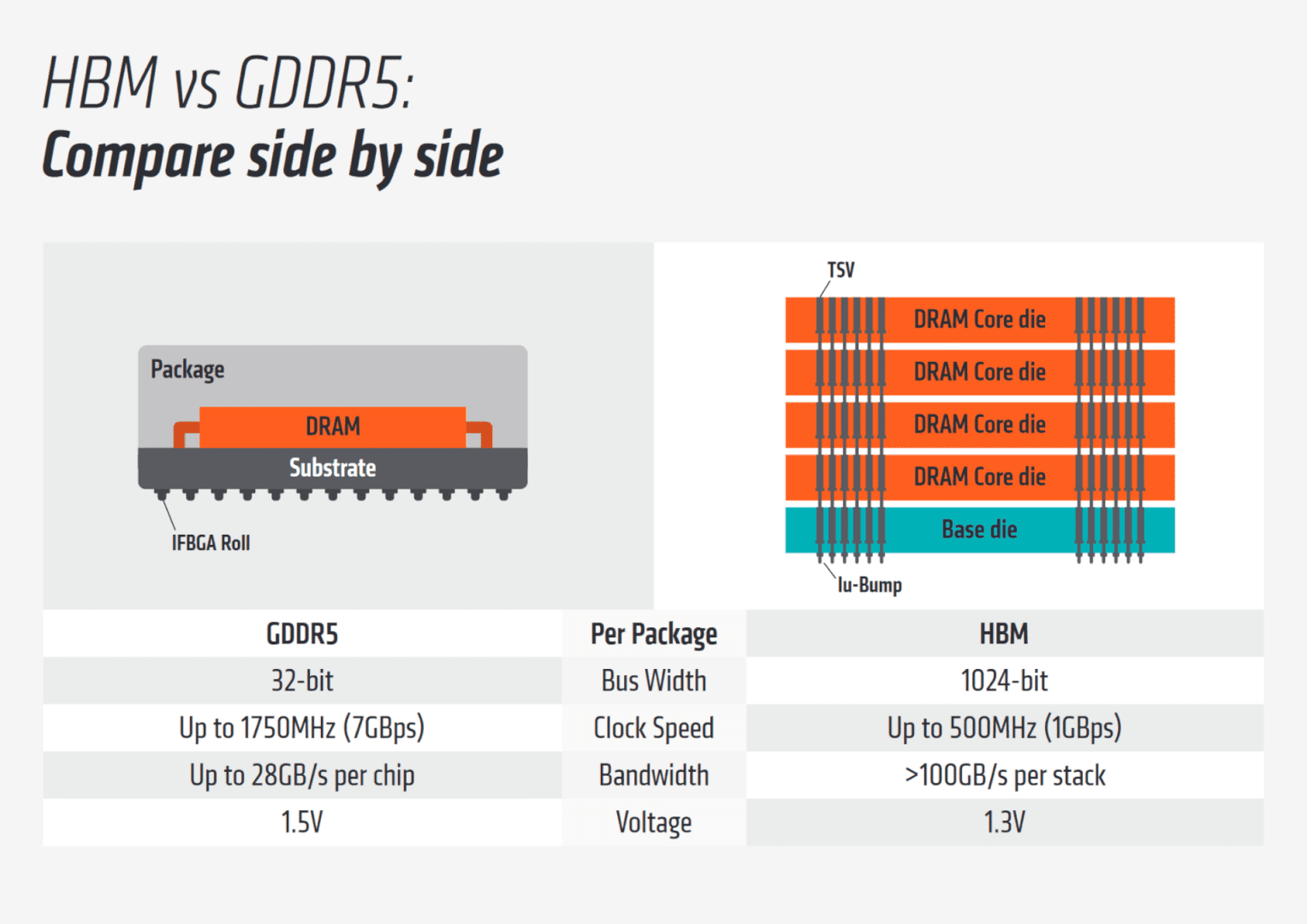
HBM adopts clocks as low as 500 MHz to conform to a low TDP target and makes up for the loss in bandwidth with a massive bus (usually 4096 bits). AMD’s Radeon RX Vega cards are the best example of HBM2 implementation in consumer hardware. HBM2 solved the 4GB limit of the HBM1, but limited yields coupled with memory shortage prevented AMD from capitalizing on the consumer GPU front.


