
AMD’s older GCN-based Vega and Polaris graphics cards can now run ray-tracing on Linux via a Mesa update. The merge request on GitHub came from Joshua Ashton, a developer of DXVK and other Direct3D-on-Vulkan projects for Valve. According to the developer, ray-tracing now works on older AMD Radeon GPUs, including Navi 10, Vega, and Polaris using a software layer that emulates the BVH intersection instructions.
It’s worth noting that this is primarily for debugging and experimental purposes, and much like NVIDIA’s older GPUs (GTX 10-series, 900-series) will be extremely slow if tested in real-time. AMD’s RDNA 2 graphics cards are the first Radeon GPUs to support BVH acceleration on a hardware level (has dedicated acceleration units), and all previous generations don’t feature any support for the same.

AMD’s RDNA 2 GPUs employ a rather interesting approach to hardware-accelerated ray-tracing. The Ray Accelerator found in each Compute Unit (2 in every WGP) accelerates ray-box and ray-triangle intersections which are the most performance-intensive parts of the ray-tracing pipeline. However, the step prior to this, BVH (tree) traversal isn’t accelerated by the RAs and is instead offloaded to the shaders (stream processors). While an optimized shader code can perform these calculations in decent render time, in other cases it can slow down the overall rendering pipeline by occupying previous render cycles that could have otherwise been used by the mesh or pixel shaders.
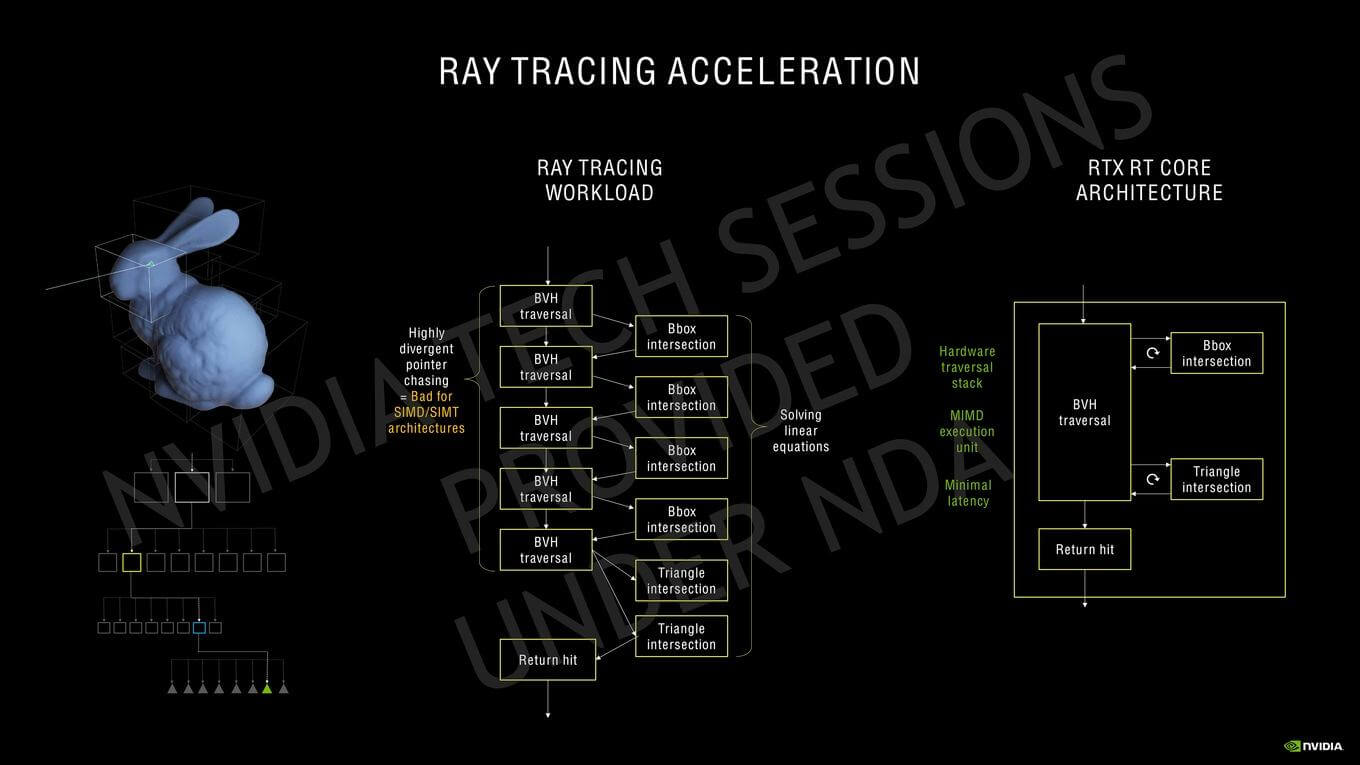
NVIDIA’s method essentially involved offloading the entire ray-tracing pipeline to the RT cores. This involves the BVH traversal, box/triangle testing as well as sending the return pointer back to the SM. The SM casts the ray, and then from there onwards to the return hit/miss, the RT core handles basically everything. Furthermore, NVIDIA’s Ampere GPUs leverage Simultaneous Computer and Graphics (SCG) which is basically another word for Async Compute. However, unlike AMD’s implementation where the compute and graphics pipelines are run together, this allows the scheduler to run ray-tracing workloads on the RT Core and the graphics/compute workload on the SM, in addition to matrix-based calculations on the Tensor cores all at once.
In comparison, AMD’s RDNA 2 design offloads the tree traversal to the SIMDs (stream processors) which likely stalls the standard graphics/compute pipeline. Although the impact can be mitigated to an extent by optimized code, it’ll still be slower than the full-fledged hardware implementation in most cases. Furthermore, NVIDIA also claims that Ampere’s 2nd Gen RT cores are twice as fast at ray-triangle intersection tests compared to Turing. Read more here.
 AMD Radeon RX 9900 XTX to Feature 18432 Cores/288 CUs: Replaces the Shelved 8900 XTX
AMD Radeon RX 9900 XTX to Feature 18432 Cores/288 CUs: Replaces the Shelved 8900 XTX AMD Radeon RX 8900 XTX Specs: 13000+ Cores for the Cancelled RDNA 4 Flagship
AMD Radeon RX 8900 XTX Specs: 13000+ Cores for the Cancelled RDNA 4 Flagship NVIDIA RTX 4080 vs 4080 Super vs 4090: 34 Benchmark Comparisons
NVIDIA RTX 4080 vs 4080 Super vs 4090: 34 Benchmark Comparisons Sapphire Pulse Radeon RX 7900 GRE Review: AMD’s Best in Action
Sapphire Pulse Radeon RX 7900 GRE Review: AMD’s Best in Action