
One of NVIDIA’s primary advantages over AMD in the consumer graphics card market is the improved ray-tracing performance. The inclusion of DLSS is another massive plus point, but it doesn’t exactly relate to the ray-tracing pipeline and can be a benefit even in scenarios where no ray-tracing is being used. Furthermore, we will likely see AMD’s Super Resolution alternative in the coming months, so the playing field should level in that respect soon enough. (Xanax)
In this post, we differentiate between AMD and NVIDIA’s approach to ray-tracing and why each of them decided to opt for a different one, and why the latter is better at it. Before we move on, please keep in mind that I consulted both the vendors before coming up with this post to avoid any miscommunication. The info contained in this article is from the official whitepapers.


Ray Tracing in AMD’s Radeon RX 6000 GPUs (RDNA 2)

AMD’s RDNA 2 GPUs employ a rather interesting approach to hardware-accelerated ray-tracing. The Ray Accelerator found in each Compute Unit (2 in every WGP) accelerates ray-box and ray-triangle intersections which are the most performance-intensive parts of the ray-tracing pipeline. However, the step prior to this, BVH (tree) traversal isn’t accelerated by the RAs and is instead offloaded to the shaders (stream processors). While an optimized shader code can perform these calculations in decent render time, in other cases it can slow down the overall rendering pipeline by occupying previous render cycles that could have otherwise been used by the mesh or pixel shaders.
As for why AMD went with this approach, the reasons are two-fold. Firstly, dedicating too much space to a dedicated hardware unit wasn’t ideal, especially since the Infinity Cache was already inflating the die size. Secondly, the company was confident that the release of Super-Resolution would offset the performance hit incurred by ray-tracing. Furthermore, AMD’s primary objective with RDNA 2 was to re-enter the high-end enthusiast GPU market that had been NVIDIA’s playground for several years now. Missing out on a few ray-traced titles wasn’t going to affect that by much, especially if you consider the previous reason.
Ray Tracing in NVIDIA’s RTX 30 Series GPUs (Ampere)
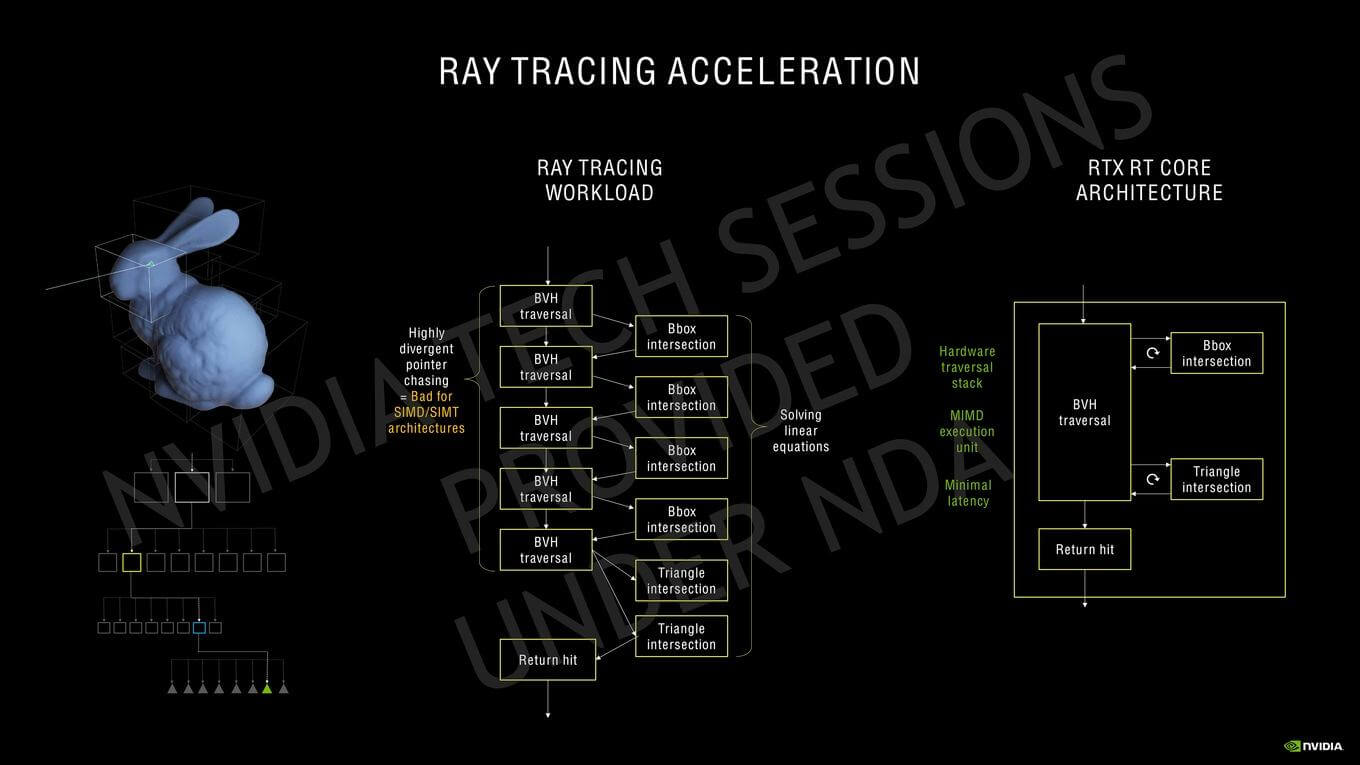
NVIDIA’s method essentially involved offloading the entire ray-tracing pipeline to the RT cores. This involves the BVH traversal, box/triangle testing as well as sending the return pointer back to the SM. The SM casts the ray, and then from there onwards to the return hit/miss, the RT core handles basically everything. Furthermore, NVIDIA’s Ampere GPUs leverage Simultaneous Computer and Graphics (SCG) which is basically another word for Async Compute. However, unlike AMD’s implementation where the compute and graphics pipelines are run together, this allows the scheduler to run ray-tracing workloads on the RT Core and the graphics/compute workload on the SM, in addition to matrix-based calculations on the Tensor cores all at once.
In comparison, AMD’s RDNA 2 design offloads the tree traversal to the SIMDs (stream processors) which likely stalls the standard graphics/compute pipeline. Although the impact can be mitigated to an extent by optimized code, it’ll still be slower than the full-fledged hardware implementation in most cases. Furthermore, NVIDIA also claims that Ampere’s 2nd Gen RT cores are twice as fast at ray-triangle intersection tests compared to Turing.


