
The specifications of AMD’s upcoming RDNA 3 GPUs have surfaced, courtesy of Angstronomics. The details of the three Navi 3X (31, 32, 33) dies have been shared by the outlet rather comprehensively. Starting with the Navi 31 die powering the Radeon RX 7900 XT, the flagship will feature one Graphics Compute Die (GCD) and six Memory Complex Dies (MCD) with 3D stacked Infinity Cache (1-hi).
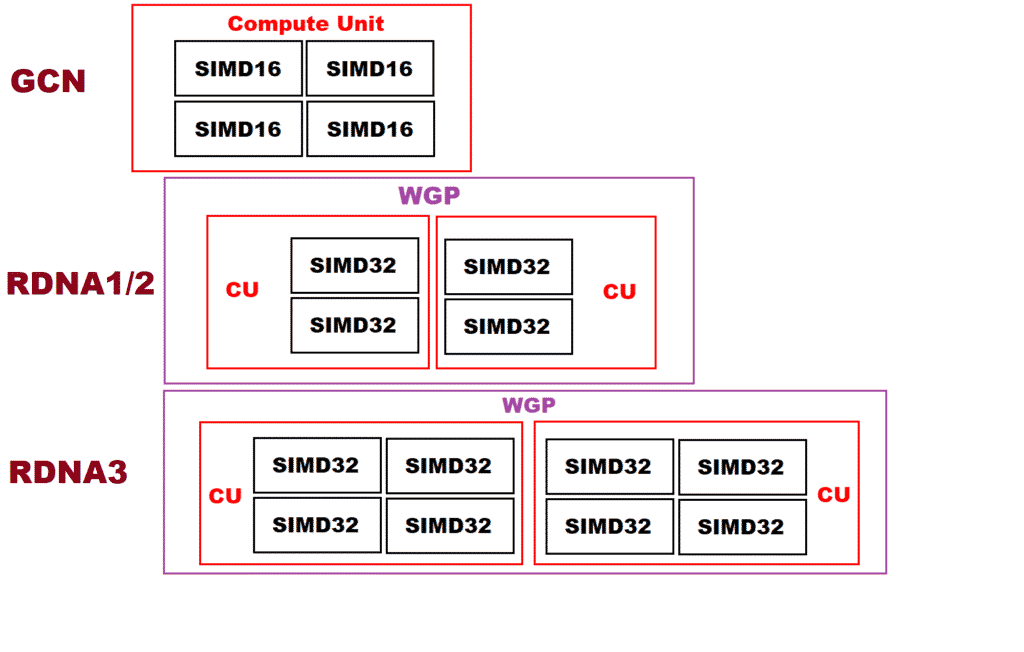
The GCD will pack 48 Work Group Processors (WGP) for a total of 12,288 shaders spread across 12 Shader Arrays and 6 Shader Engines. Each of the MCDs will feature 16MB of L3 “Infinity” cache and a 64-bit memory controller for a total of 96MB and a 384-bit bus. The LLC is doubled by 3D stacking the cache dies upon the MCDs for an overall SRAM of 192MB. A cut-down variant of the die will feature 42 WGPs (10,752 cores) and five MCDs with 80MB of cache and a bus width of 320-bit. This may turn out to be the RX 7800 XT or the 7850 XT.



Moving to Navi 32 or the RX 7800 XT, we’re looking at 30 WGPs for 7,680 cores alongside a 256-bit bus and 64MB of LLC. The GPU core will be paired with 4 MCDs instead of 6 without any 3D stacked cache dies. Finally, we have Navi 33 set to power the RX 7700 XT. This will be a monolithic GPU with 16 WGPs or 4,096 cores and 32MB of Infinity Cache cache paired with a 128-bit bus.
RDNA 3 will once again overhaul the Compute Unit, stuffing as many as 128 shaders across four SIMD32 units. The Work Group Processor, in turn, packs a total of 256 stream processors across eight SIMDs. As we know, AMD switched to a shorter 32-thread dispatch with RDNA, down from 64 on GCN. Known as wave32, it schedules 32 work items per SIMD for a total of 32 x2 per CU and 32 x4 per WGP.
The whole point of this shakeup was the improve utilization and maximize the number of data sets being scheduled. With GCN, each Compute Unit would work on four 64-item waves, not one 64-item wave. Like Bulldozer, the aim was to maximize parallelization. At the same time, GCN wasn’t an out-of-order architecture. The instructions within a wavefront were still executed as per their order. The only advantage was that the CU or SIMDs could switch to any of the four available waves.
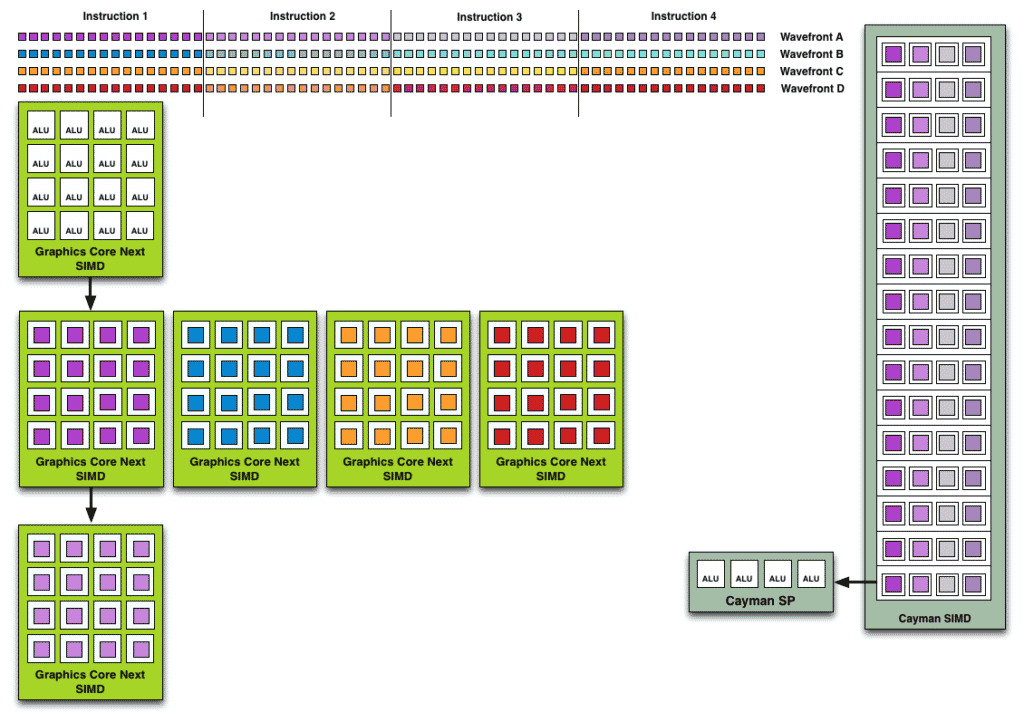
The reason why this wasn’t very effective is that most games use shorter work queues due to which only one or two out of the four wavefronts were saturated per execution cycle. As a result, AMD’s GCN scheduler had to wait for four cycles for the next wave despite having room for additional wavefronts. RDNA fixes this by reducing the wave size and increasing the wave count. RDNA 3 doubles down on this by literally doubling the number of concurrent 32-item waves per CU and WGP.


