
A new patent was recently published on workload distribution on heterogeneous processors, giving us a glimpse into Alder Lake’s possible workload scheduler. The patent includes details pertaining to the resource allocation mechanism on hybrid core architectures with a hardware-guided scheduling interface which keeps the OS up to date on the capabilities of the processor based on power, thermal and other constraints of the various cores available.
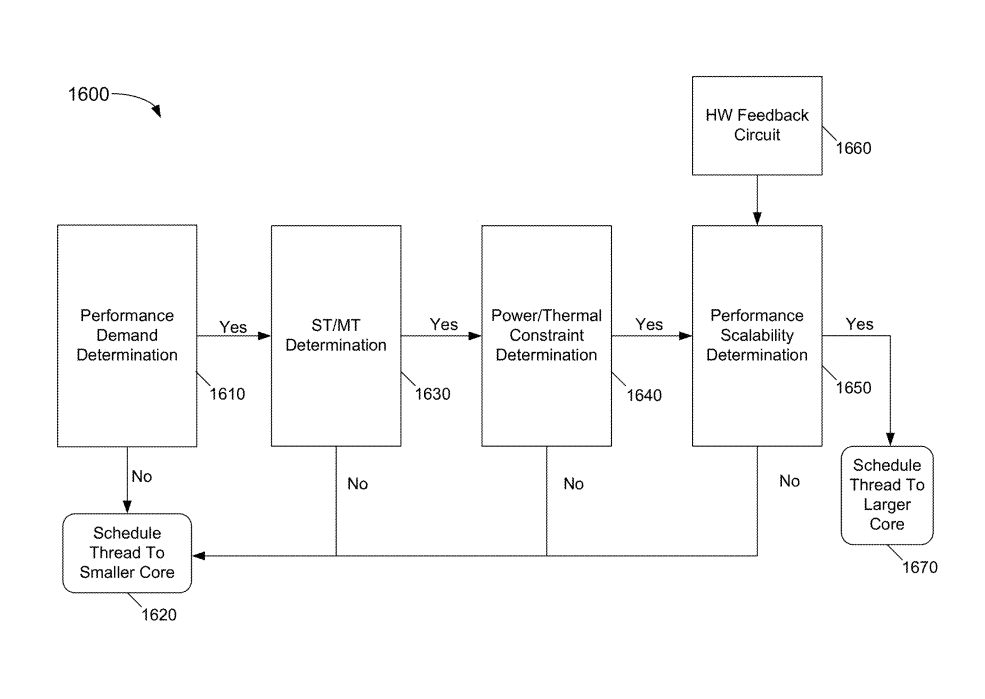
The workload scheduler works by identifying the most demanding thread running on the system (by time or resource requirement) and assigns it to the high-performance cores while the other threads are delegated to the low-power cores. In the first pass, the performance requirement of the scheduled workload is calculated using thread data such as run time, priority, and latency associated with them. If the algorithm decides that the workload doesn’t require the additional resources of the high-performance cores, then the thread is assigned to the low-power cores.

After this, the nature of the thread is determined, with an aim to figure out whether the thread I question is a single independent thread or the primary thread of a larger group. Here, the thread is assigned to the performance or power cluster depending on which one increases the resulting system throughput. It’s worth noting that this value will depend on the state of the system, the number of cores being utilized as well as the power consumption of the processor at the time.
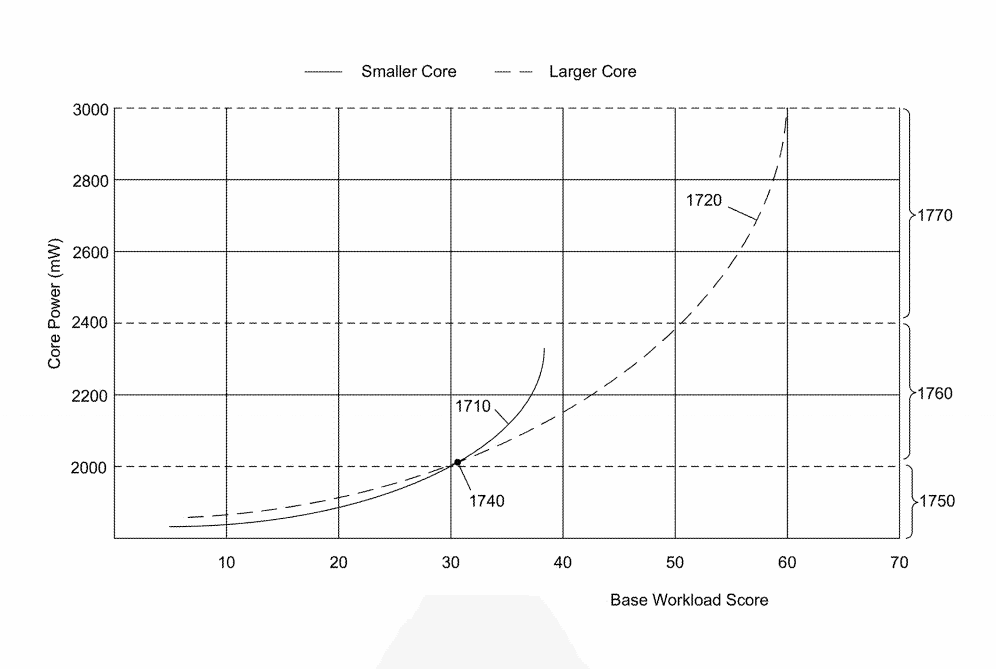
Finally, the scalability of the thread is analyzed. As you can see in the above graph, the small core draws less power than the big core up until a certain point, in this case, up to 30 base workload score. After this, the low core loses its efficiency in executing the more complex workloads and anything north of 32-33 (in this case) is better left for the big cores. This may be due to various reasons, including instruction support, execution units, the difference in the registers of the two cores, re-order buffers, etc.
Source (Via: CoreTeks)

