
AMD’s RDNA 3 graphics architecture is expected to get a major design change on the front-end, with redesigned Work Group Processors and no Compute Units, or Dual Compute Units for that matter. With RDNA 1 and 2, the WGPs were the basic units for workload scheduling (from CUs on GCN/Vega), but it looks like that is changing once again with Navi 3x. Dual Compute Units are being discarded in favor of wider Work Group Processors, packing as many as 256 stream processors across eight 32-wide SIMDs.
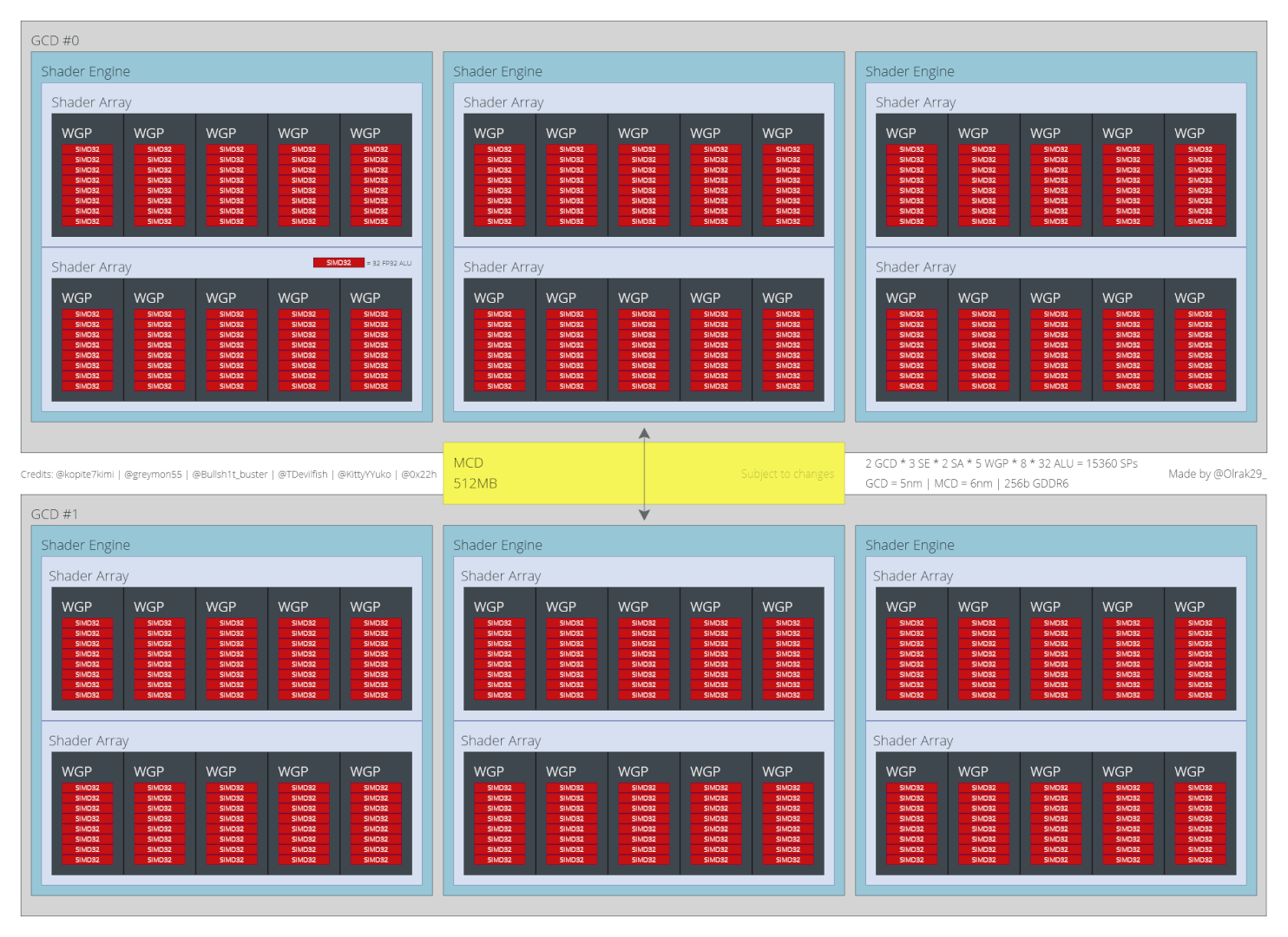
With Navi 31, each Graphics Die (GCD) features three Shader Engines which are made up of two Shader Arrays each. In turn, each Shader Array packs five WGPs containing eight SIMD units (vs four on RDNA 2). The two dies are connected by a bridge interconnect paired with 512MB of L3 “Infinity” Cache. According to the source, the GCDs will be fabbed on TSMC’s 5nm (N5) node while the MCD will be fabbed on the older 6nm (N6) node. Each die should come with a 128-bit bus (divided into eight controllers), resulting in an overall bus width of 256-bit and the same external bandwidth of 448GB/s as the RX 6800 XT/6900XT.

In comparison, Navi 21 featured a Shader Engine packing 10 Dual Compute Units (20 Compute Units) which was in turn divided into two SIMDs per CU or four per DCU. Each CU featured its own vector and scalar units, along with a ray-accelerator, texture mapping units, registers, and cache. Scheduling was done on a WGP (DCU) basis, meaning four wave32 workgroups were assigned at a time. With Navi 3x, scheduling will become more complex as you’re taking 8 SIMDs or wave32 workgroups into account at once.



