
There’s a third, less commonly used cache policy called non-inclusive non-exclusive (NINE). Here the blocks are neither inclusive nor exclusive of the higher-level cache. Let’s consider the same example one last time. There’s a request for block X and it’s found in L1. Then the CPU core will read and consume this block from the L1 cache. If the block isn’t found in L1 but is present in L2, then it’s fetched from L2 to L1. The L2 cache remains unchanged similar to how inclusive cache works.
However, if the block isn’t found in either cache level, then it’s fetched from the main memory and placed in both L1 and L2. However, if this results in the eviction of a block from L2, unlike inclusive cache, there’s no back invalidation to the L1 cache to nuke the same block from there.


A Look at Memory Mapping
With the basic explanations about cache out of the way, let’s talk about how the system memory talks to the cache memory. This is called cache or memory mapping. The cache memory is divided into blocks or sets. These blocks are in turn divided into n 64-byte lines. The system memory is divided into the same number of blocks (sets) as the cache and then the two are linked.
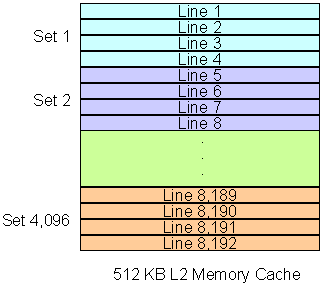
If you have 1GB of system RAM, then the cache will be divided into 8,192 lines and then separated into blocks. This is called n-way associative cache. With a 2-way associate cache, each block contains two lines each, 4-way includes four lines each, eight lines for 8-way, and sixteen lines for 16-way. Each block in the memory will be 512 KB in size if the total RAM size is 1GB.
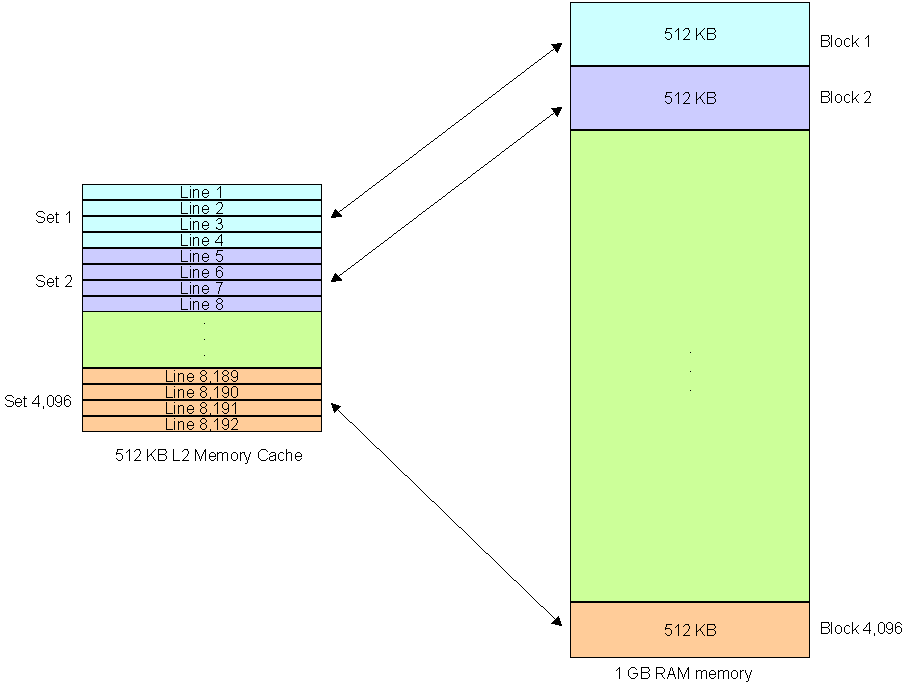
If you have 512 KB of 4-way associated cache, the RAM will be divided into 2,048 blocks (8192/4 for 1GB) and linked to the same number of 4-line cache blocks.
In the same way with 16-way associative cache, the cache is divided into 512 blocks linked to 512 (2048 KB) blocks in the memory, each cache block containing 16 lines. When the cache runs out of data blocks, the cache controller reloads a new set of blocks with the required data to continue processor execution.
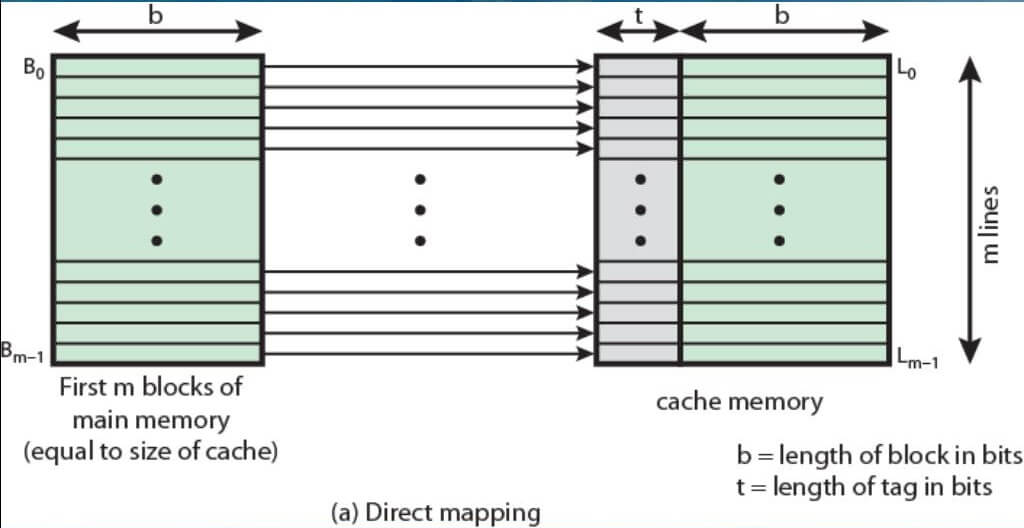
N-way associative cache is the most commonly used mapping method. There are two more methods known as direct mapping and fully associated mapping. In the former, there is hard-linking between the cache lines and memory while in the case of the latter, the cache can contain any memory address. Basically, each line can access any main memory block. This method has the highest hit rate. However, it’s costly to implement and as a result, is mostly avoided by chipmakers.
Which Mapping is the Best?
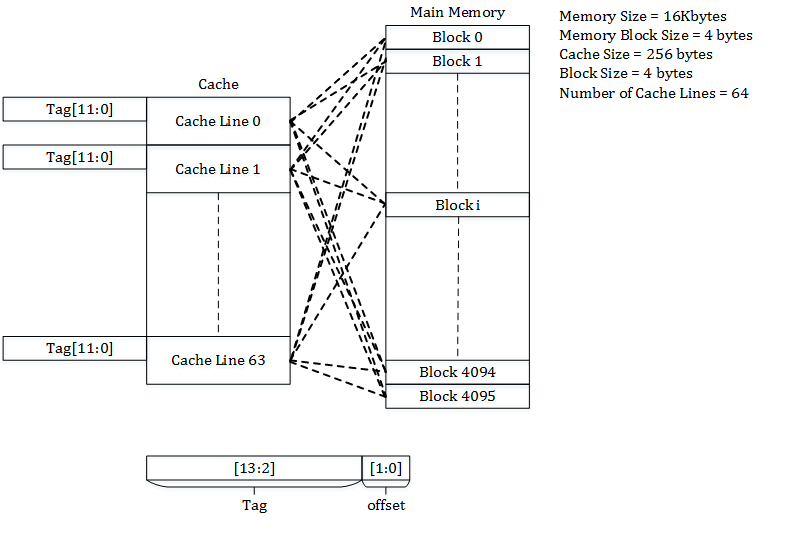
Direct mapping is the easiest configuration to implement, but at the same time is the least efficient. For example, if the CPU asks for a given memory address (1,000 in this case), the controller will load a 64-byte line from the memory and store it on the cache (1,000 to 1,063). In the future, if the CPU requires data from the same addresses or the addresses right after this one (1,000 to 1,063), they will already be in the cache.
This becomes a problem when the CPU needs two addresses one after the next that are in the memory block mapped to the same cache line. For example, if the CPU first asks for address 1,000 and then asks address 2,000, a cache miss will occur because these two addresses are inside the same memory block (128 KB being the block size). The cache line mapped to it, on the other hand, was a line starting from address 1,000 to 1,063. So the cache controller will load the line from address 2,000 to 2,063 in the first cache line, evicting the older data. That is the reason why direct mapping cache is the least efficient cache mapping technique and has largely been abandoned.
Fully associative mapping is somewhat the opposite of Direct Mapping. There is no hard linking between the lines of the memory cache and the RAM memory locations. The cache controller can store any address. There the above problem doesn’t happen. This cache mapping technique is the most efficient, with the highest hit rate. However, as already explained, it’s the hardest and most expensive to implement.
As a result, set-associative mapping which is a hybrid between fully associative and direct mapping is used. Here, every block of memory is linked to a set of lines (depending on the kind of SA mapping), and each line can hold the data from any address in the mapped memory block. On a 4-way set-associative cache each set on the memory cache can hold up to four lines from the same memory block. With a 16-way config, that figure grows to 16.
When the slots on a mapped set are all used up, the controller evicts the contents of one of the slots and loads a different set of data from the same mapped memory block. Increasing the number of ways a set-associative memory cache has, for example, from 4-way to 8-way, you have more cache slots available per set. However, if you don’t increase the amount of cache, the memory size of each linked memory block increases. Basically, increasing the number of available slots on set cache set without increasing the overall cache size means that set would be linked to a larger memory block, effectively reducing efficiency due to an increased number of flushes.
On the other hand, increasing the cache size means that you’d have more lines in each set (assuming the set size is also increased). This means a higher number of linked cache lines for every memory block. Generally, this increases the hit rate but there’s a limit to how much it can improve the overall figure.
