
Every modern processor features a small amount of cache memory. Over the past few decades, cache architectures have become increasingly complex: The levels of CPU cache have increased to three: L1, L2, and L3, the size of each block has grown and the cache associativity has undergone several changes as well. But before we dive into the specifics, you must know what exactly is cache memory and why is it important? Furthermore, modern processors consist of L1, L2, and L3 cache. What’s the difference between these cache levels?


Cache Memory vs System Memory: SRAM vs DRAM
Cache memory is based on the much faster (and expensive) Static RAM while system memory leverages the slower DRAM (Dynamic RAM). The main difference between the two is that the former is made of CMOS technology and transistors (six for every block) while the latter uses capacitors and transistors.
DRAM needs to be constantly refreshed (due to leaking charges) to retain data for longer periods. Due to this, it draws significantly more power and is slower as well. SRAM doesn’t have to be refreshed and is much more efficient. However, the higher pricing has prevented mainstream adoption, limiting its use to processor cache.
Importance of Cache Memory in Processors?
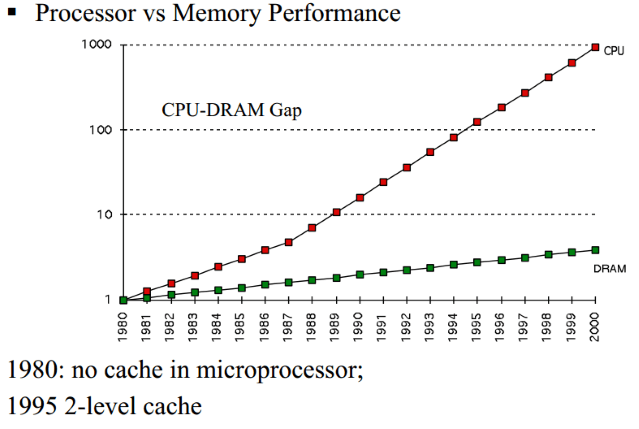
Modern processors are light years ahead of their primitive ancestors that were around in the 80s and early 90s. These days, top-end consumer chips run at well over 4GHz while most DDR4 memory modules are rated at less than 1800MHz. As a result, system memory is too slow to directly work with CPUs without severely slowing them down. This is where the cache memory comes in. It acts as an intermediate between the two, storing small chunks of repeatedly used data or in some cases, the memory addresses of those files.
L1, L2 and L3 Cache: What’s the Difference?
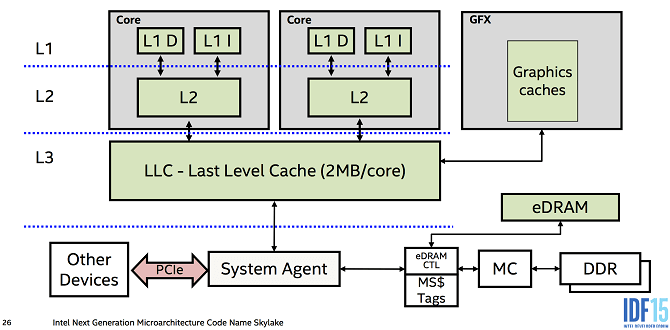
In contemporary processors, cache memory is divided into three segments: L1, L2, and L3 cache, in order of increasing size and decreasing speed. L3 cache is the largest and also the slowest (the 3rd Gen Ryzen CPUs feature a large L3 cache of up to 64MB) cache level. L2 and L1 are much smaller and faster than L3 and are separate for each core. Older processors didn’t include a third-level L3 cache and the system memory directly interacted with the L2 cache:
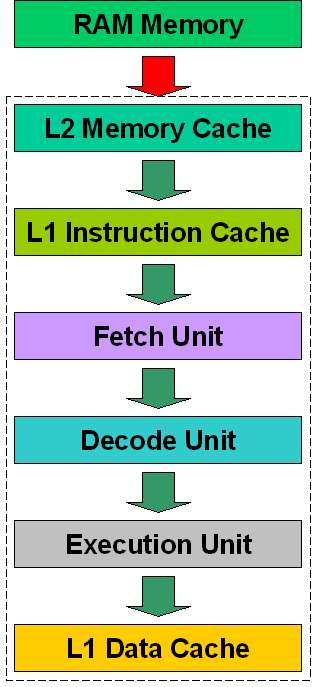
L1 cache is further divided into two sections: L1 Data Cache and L1 Instruction Cache. The latter contains the instructions that will be consumed by the CPU core while the former is used to hold data that will be written back to the main memory.
L1 cache not only works as the instruction cache, but it also holds pre-decode data and branching information. Furthermore, while the L1 data cache often acts as an output-cache, the L1 instruction cache behaves like an input-cache. This is helpful when loops are engaged as the required instructions are right next to the fetch unit.

Modern CPUs include up to 512KB of L1 cache (64KB per core) for flagship processors while server parts feature almost twice as much.
L2 cache is much larger than L1 but at the same time slower as well. They range from 4-8MB on flagship CPUs (512KB per core). Each core has its own L1 and L2 cache while the last level, the L3 cache is shared across all the cores on a die.
L3 cache is the lowest-level cache. It varies from 10MB to 64MB. Server chips feature as much as 256MB of L3 cache. Furthermore, AMD’s Ryzen CPUs have a much larger cache size compared to rival Intel chips. This is because of the MCM design vs Monolithic on the Intel side. Read more on that here.
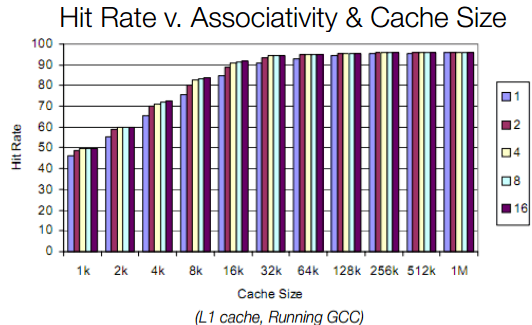
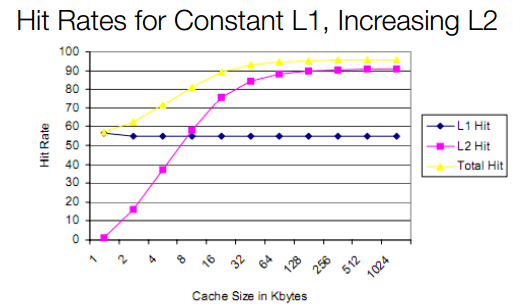
When the CPU needs data, it first searches the associated core’s L1 cache. If it’s not found, the L2 and L3 caches are searched next. If the necessary data is found, it’s called a cache hit. On the other hand, if the data isn’t present in the cache, the CPU has to request it to be loaded onto the cache from the main memory or storage. This takes time and adversely affects performance. This is called a cache miss.
Generally, the cache hit rate improved when the cache size is increased. This is especially true in the case of gaming and other latency-sensitive workloads.
Inclusive vs Exclusive Cache
The cache configuration is of two types: inclusive and exclusive cache. If all the data blocks present in the higher-level cache (L1) are present in the lower-level cache (L2), then the low-level cache is known as inclusive of the higher-level cache.
On the other hand, if the lower-level cache only contains data blocks that aren’t present in the higher-level cache, then the cache is said to be exclusive of the higher-level cache.
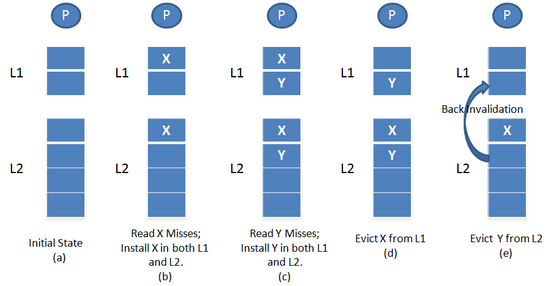
Consider a CPU with two levels of cache memory. Now, suppose a block X is requested. If the block is found in the L1 cache, then the data is read from the L1 cache and consumed by the CPU core. However, if the block is not found in the L1 cache, but is present in L2, then it’s fetched from the L2 cache and placed in L1.
If the L1 cache is also full, a block is evicted from L1 to make room for the newer block while the L2 cache is unchanged. However, if the data block is found neither in L1 and L2, then it’s fetched from the memory and placed in both the cache levels. In this case, if the L2 cache is full and a block is evicted to make room for the new data, the L2 cache sends an invalidation request to the L1 cache, so the evicted block is removed from there as well. Due to this invalidation procedure, an inclusive cache is slightly slower than a non-inclusive or exclusive cache.

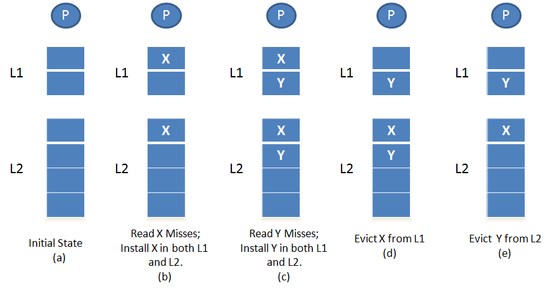
Now, let’s consider the same example with non-inclusive or exclusive cache. Let’s suppose that the CPU core sends a request for block X. If block X is found in L1, then it’s read and consumed by the core from that location. However, if block X is not found in L1, but present in L2, then it’s moved from L2 to L1. If there’s no room in L1, one block is evicted from L1 and stored in L2. This is the only way L2 cache is population, as such acts as a victim cache. If block X isn’t found in L1 or L2, then it’s fetched from the memory and placed in just L1.
Continue reading on the next page…

