
Most of the computation in AMD’s GCN and RDNA architectures is performed by the SIMDs which happen to be vector in nature: perform a single instruction on multiple data types (32 INT/32 FP executed per SIMD per cycle, simultaneously). However, there are scalar units in each CU as well. Each Compute Unit in RDNA 1 can launch (dispatch) four instructions per cycle, two scalars, two vectors. Within an RDNA1 WGP, the total throughput is 128 vectors and 4 scalars per clock. Each of the four SIMDs contributes equally to that figure.

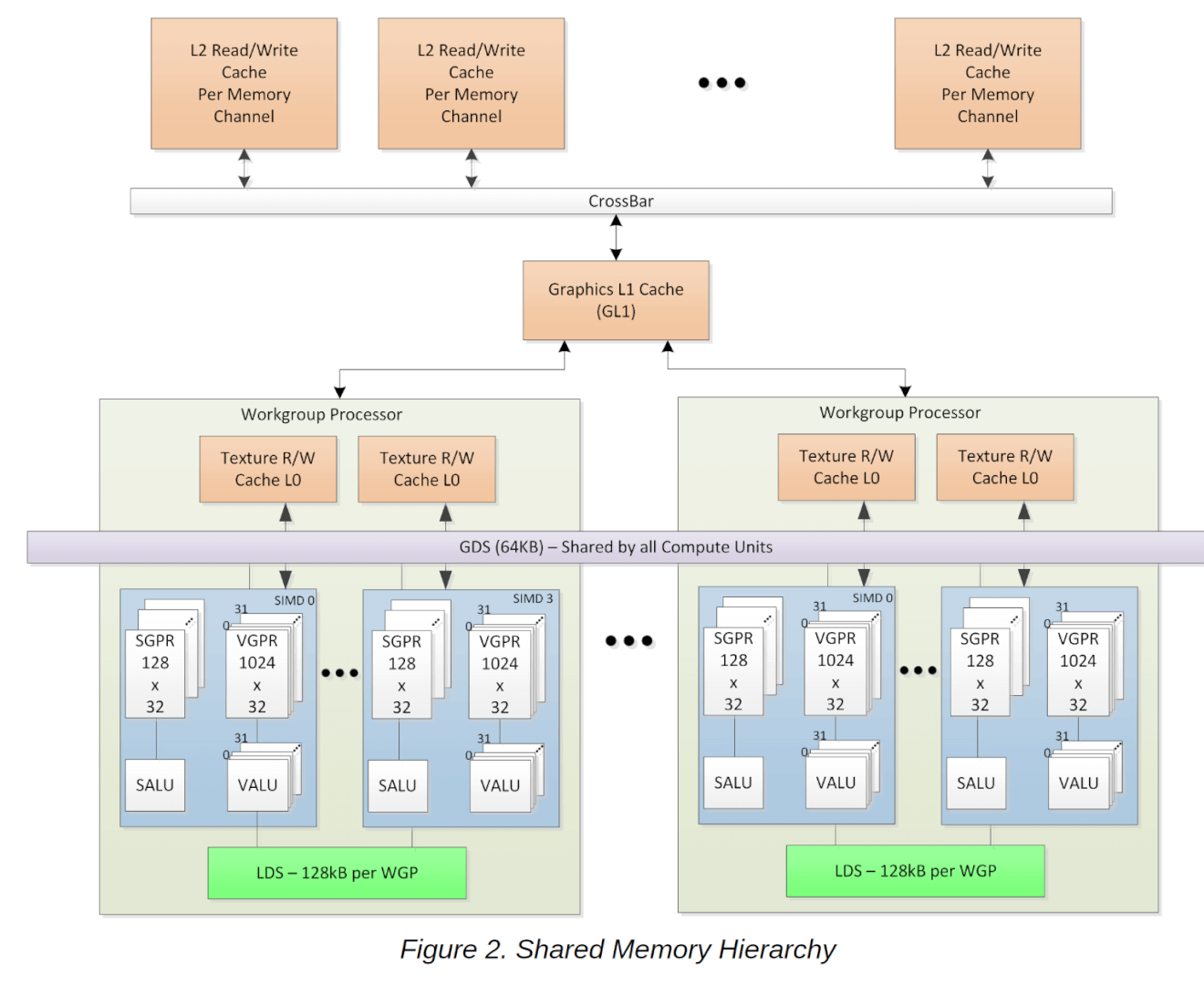
Each SIMD contains a 10KB scalar register file, with 128 entries for each of the 20 wavefronts. A register is 32-bits wide and can hold packed 16-bit data (integer or floating-point) and adjacent register pairs hold 64-bit data. The scalars are used for address generation for the load/store units and manage the SIMD control flow.


When a wavefront is initiated, the scalar register file can preload up to 32 user registers to pass constants, avoiding explicit load instructions and reducing the launch time for wavefronts.

The 16KB write-back scalar cache is 4-way associative and built from two banks of 128 cache lines that are 64B each. Each bank can read a full cache line, and the cache can deliver 16B per clock to the scalar register file in each SIMD. For graphics shaders, the scalar cache is commonly used to stored constants and work-item independent variables.
Cache: L0 & Shared L1
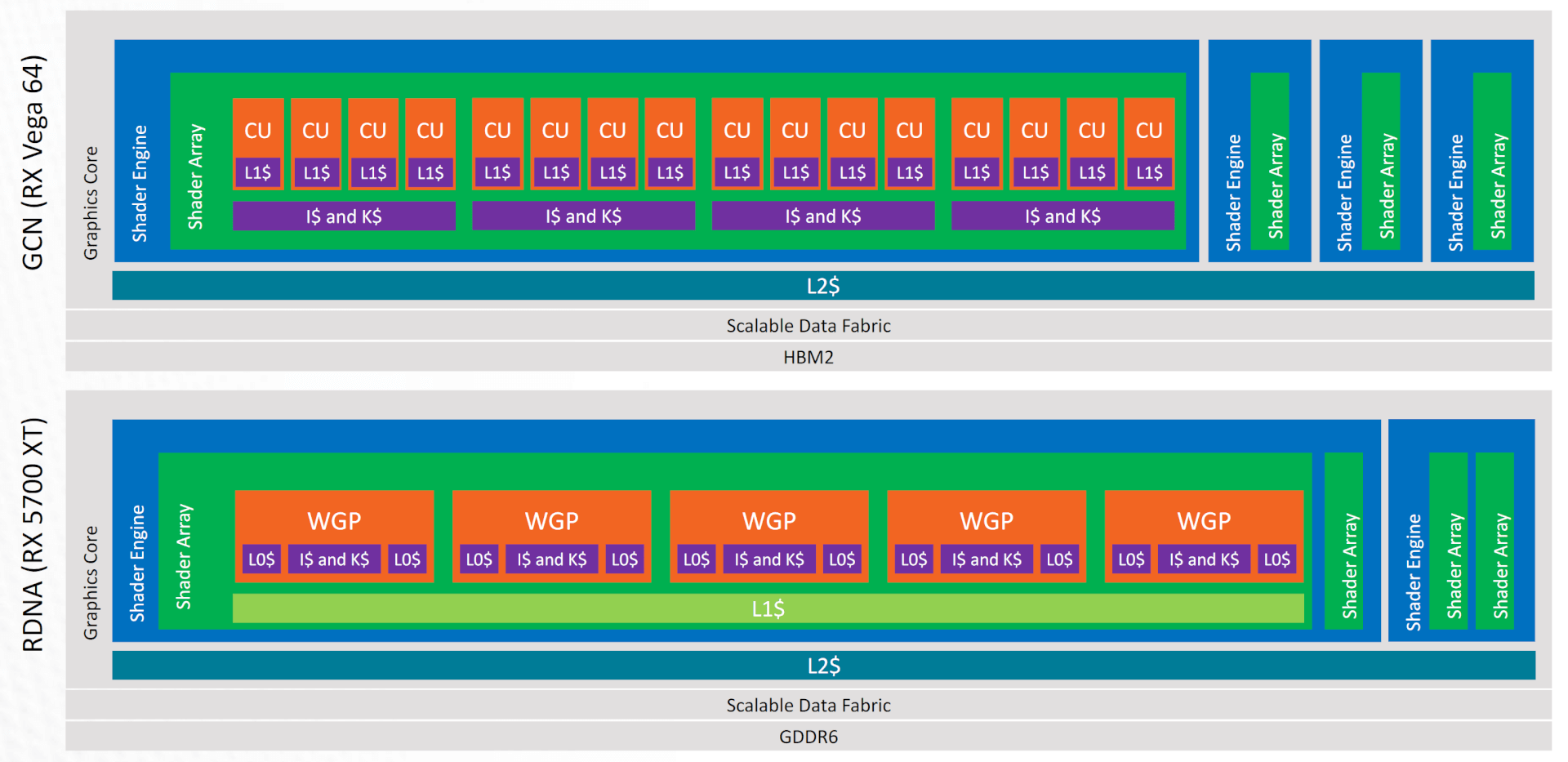
While the old GCN and rival NVIDIA GPUs rely on two levels of cache: RDNA adds a third L1 cache in the Navi GPUs. Where the L0 cache is private to a DCU, the L1 cache is shared across a group of Dual Compute Units. This reduces costs, latency, and power consumption. It reduces the load on the L2 cache. In GCN, all the cache misses of the per-core L1 cache were handled by the L2 cache. In RDNA, the new L1 cache centralizes all caching functions within each shader array.
While the L0 cache is private to a DCU, the L1 cache is shared across a group of Dual Compute Units.
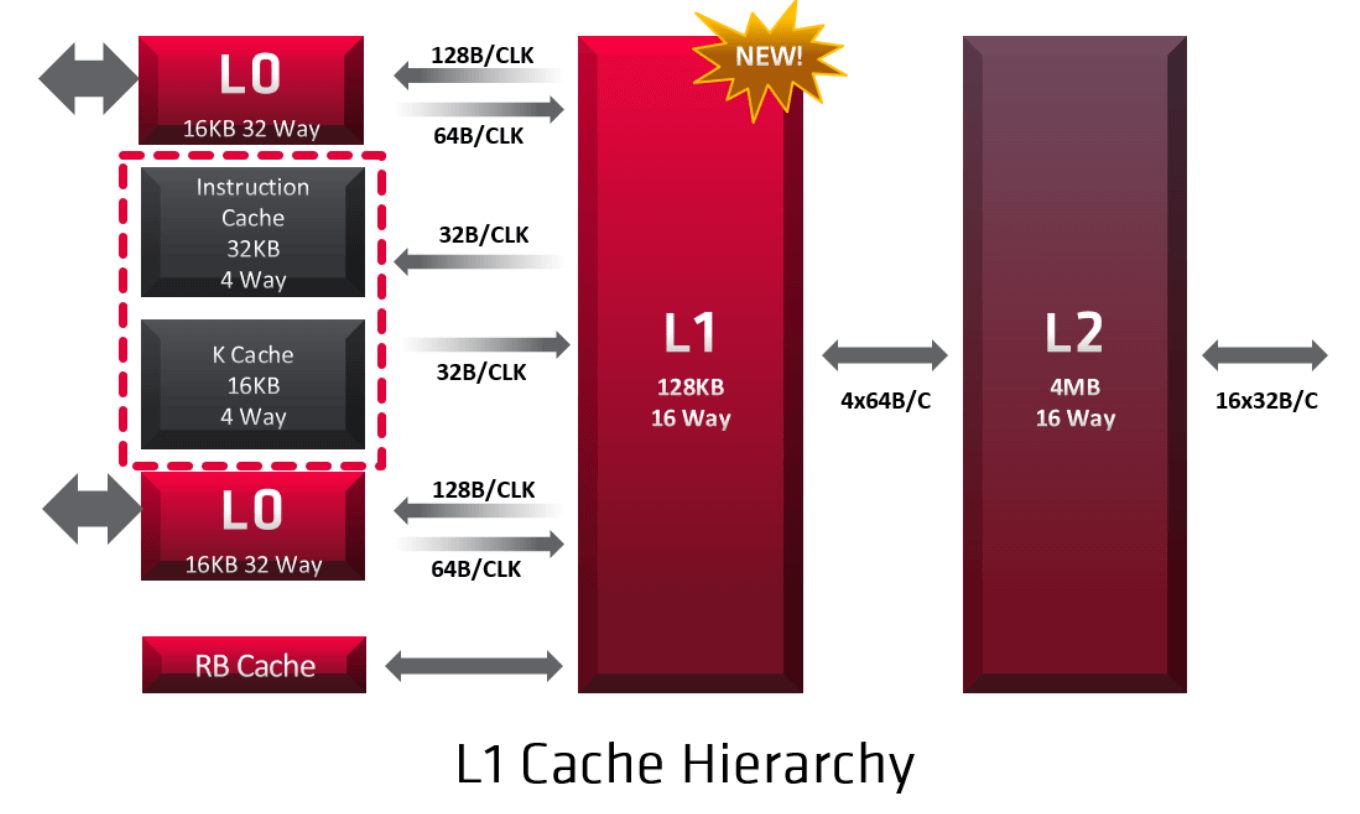
Any cache misses that happen in the L0 caches pass to the L1 cache. This includes all the data from the instruction, scalar, and vector caches, in addition to the pixel cache. L1 is a read-only cache and each is composed of four banks, resulting in a total of 128KB. It is a 16-way set-associative cache memory. The L1 cache is backed by the L2; a write to L1 will be invalidated and copied to L2 or memory.
The L1 cache controller coordinates memory requests and forwards four per clock cycle, one to each L1 bank. Like in any other cache memory, L1 misses are serviced by the L2 cache.
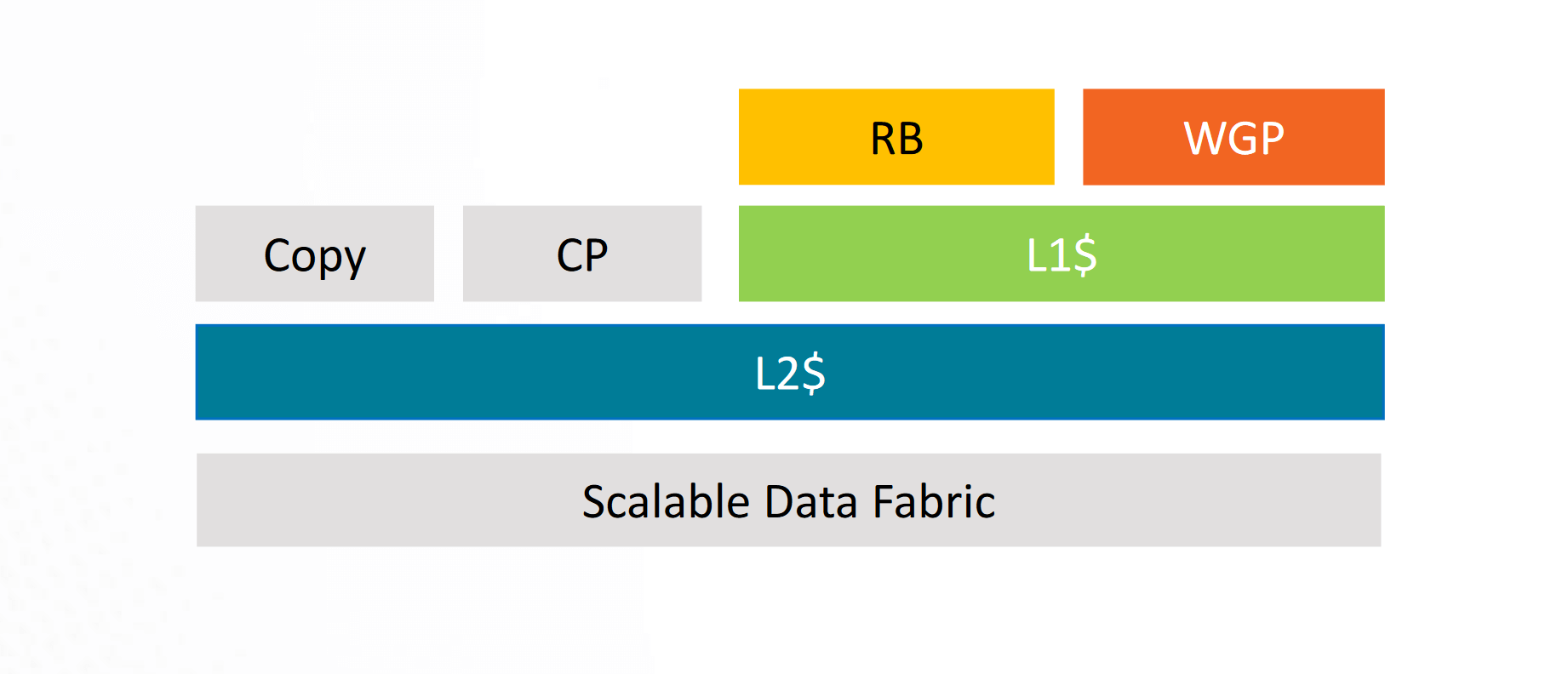
On the Polaris GPUs, only the Compute Units were the clients of the L2 cache. The RBs, Copy Engine, and CP wrote directly to the memory, resulting in lots of L2 flushes. Vega refined this design by making the RBs clients of the L2 as well, thereby reducing L2 flushes. RDNA and Navi go a step ahead of the GCN derivatives by making the copy engine a client of L2 as well. This should result in very few L2 flushes.
Dual Compute Unit Front End
Each Compute Unit fetches instructions via the Instruction Memory Fetch. In GCN, the instruction cache was shared between four CUs, but in RDNA (Navi), the L0 instruction cache is shared amongst the four SIMDs in a Dual CU. The instruction cache is 32KB and 4-way set-associative. Like the L1, it is organized into four banks of 128 cache lines, each 64-bytes long.
In GCN, the instruction cache was shared between four CUs, but in RDNA (Navi), the L0 instruction cache is shared amongst the four SIMDs in a Dual CU.
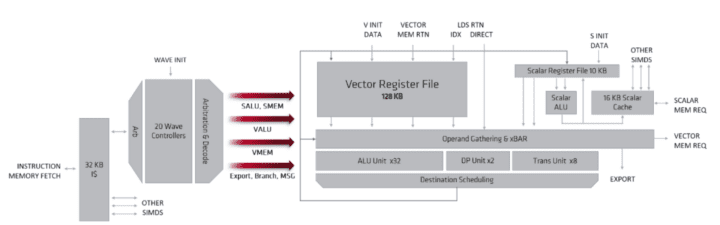
The fetched instructions are deposited into the wavefront controllers. Each SIMD has a separate instruction pointer and a 20-entry wavefront controller, for a total of 80 wavefronts per dual compute unit. Wavefronts may be different from a work group or kernel. Although a higher number of wavefronts may be fetched, a dual-compute unit works on only two wave32 workgroups simultaneously.

As already mentioned, where GCN requested instructions once every four cycles, Navi does it every cycle (2-4 ins per cycle). After that, each SIMD in an RDNA based Navi GPU can decode and issue instructions every cycle as well, increasing the throughput and reducing latency by 4x over GCN.
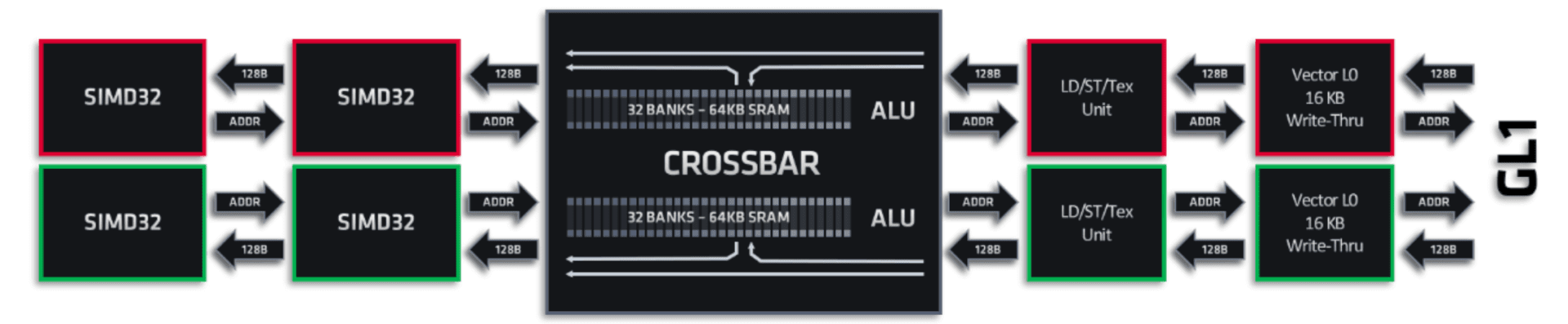
To accommodate the new wave32 mode, the cache and memory pipelines in each RDNA SIMD have also been revamped. The pipeline width has been doubled compared to GCN-based Vega GPUs. Every SIMD has a 32-wide request bus that can transmit the address for a work-item in a wavefront directly to the ALUs or the vGPRs (Vector General Purpose Registers).
A pair of SIMDs share a request and return bus, however, a single SIMD can receive two chunks of 128B cache lines per clock: one from the LDS (Load-Store) and the other from the Vector L0 cache.
Render Back End (RBs) and Texture Units
The final fixed-function graphics stage in an RDNA based Navi GPU is the Render Backend (RB), which performs depth, stencil, and alpha tests and blends pixels for anti-aliasing and other final tests. Each of the RBs in the shader array can test, sample, and blend pixels at a rate of four output pixels per clock. The major improvement in the RDNA architecture here is that the RBs access data through the graphics L1 cache, which reduces the pressure on the L2 cache and saves power by moving fewer data. Recall, how in GCN, the RBs wrote data directly to the memory, then in Vega via the L2 cache.
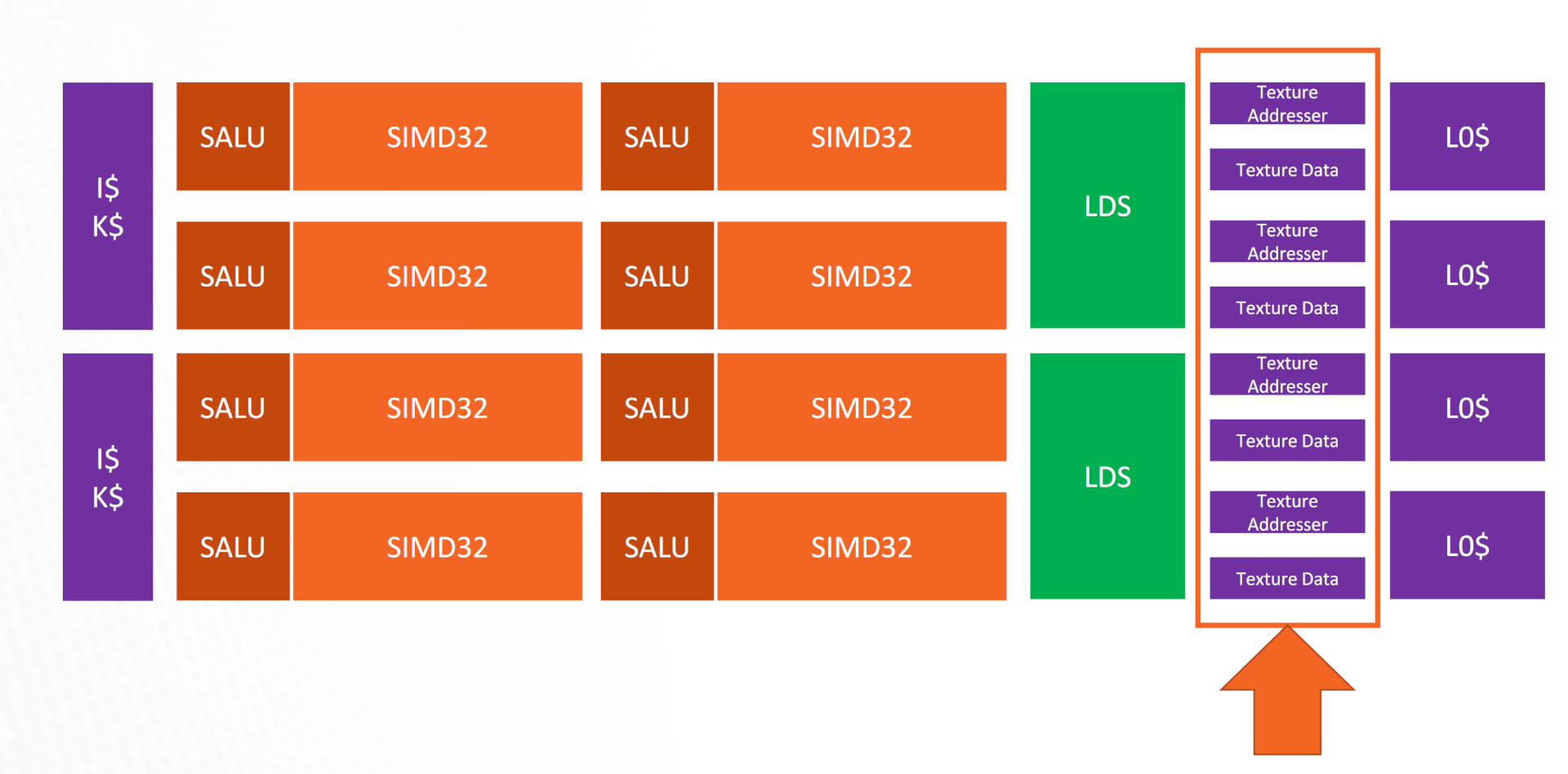
The Texture Units have also received a significant uplift with RDNA and Navi. The load and store processing speeds are multiple times faster compared to GCN, making it easier for the GPU to reach maximum bandwidth via both loads and stores.
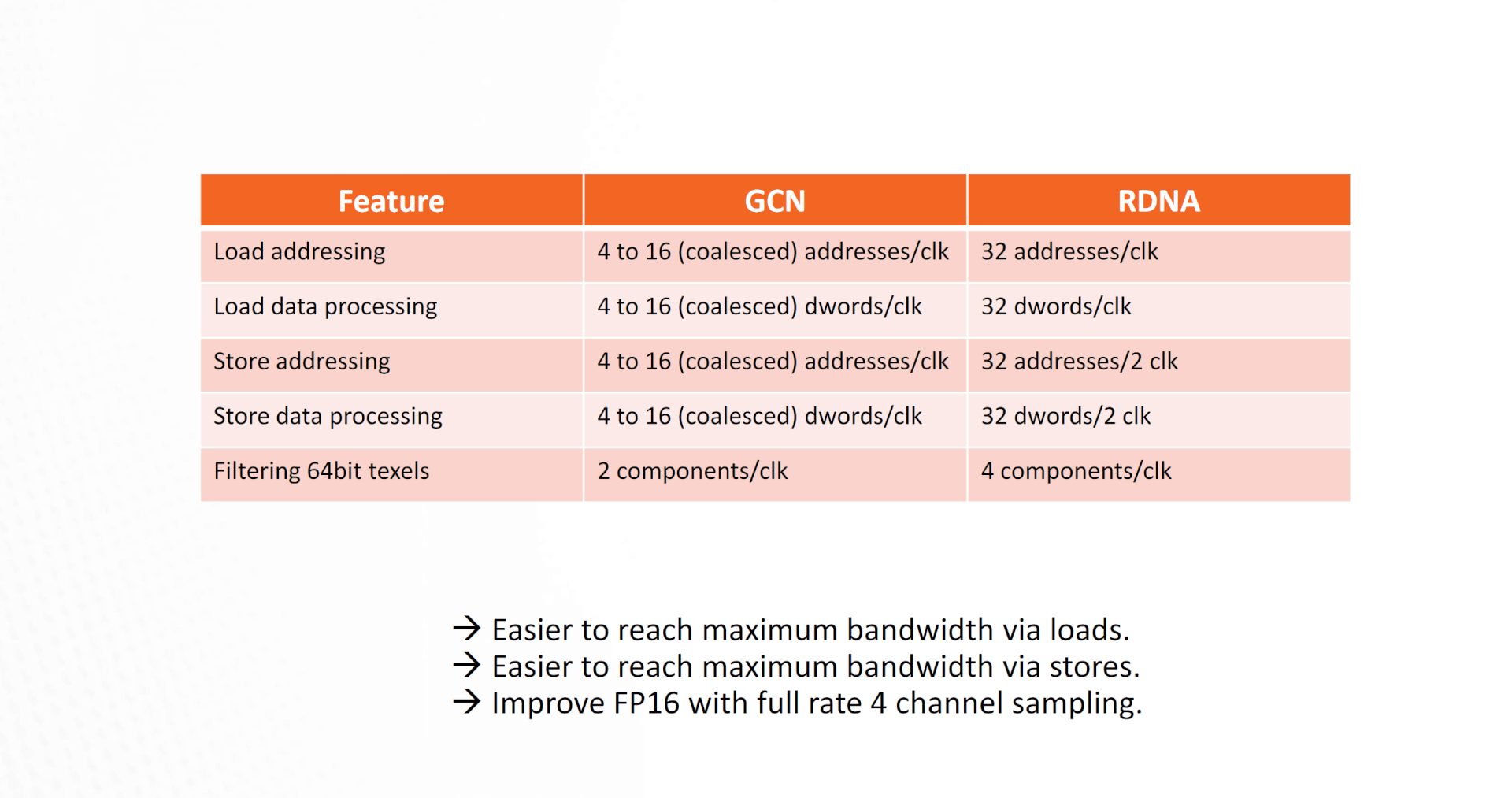
RDNA vs GCN: ALU Utilization Comparison
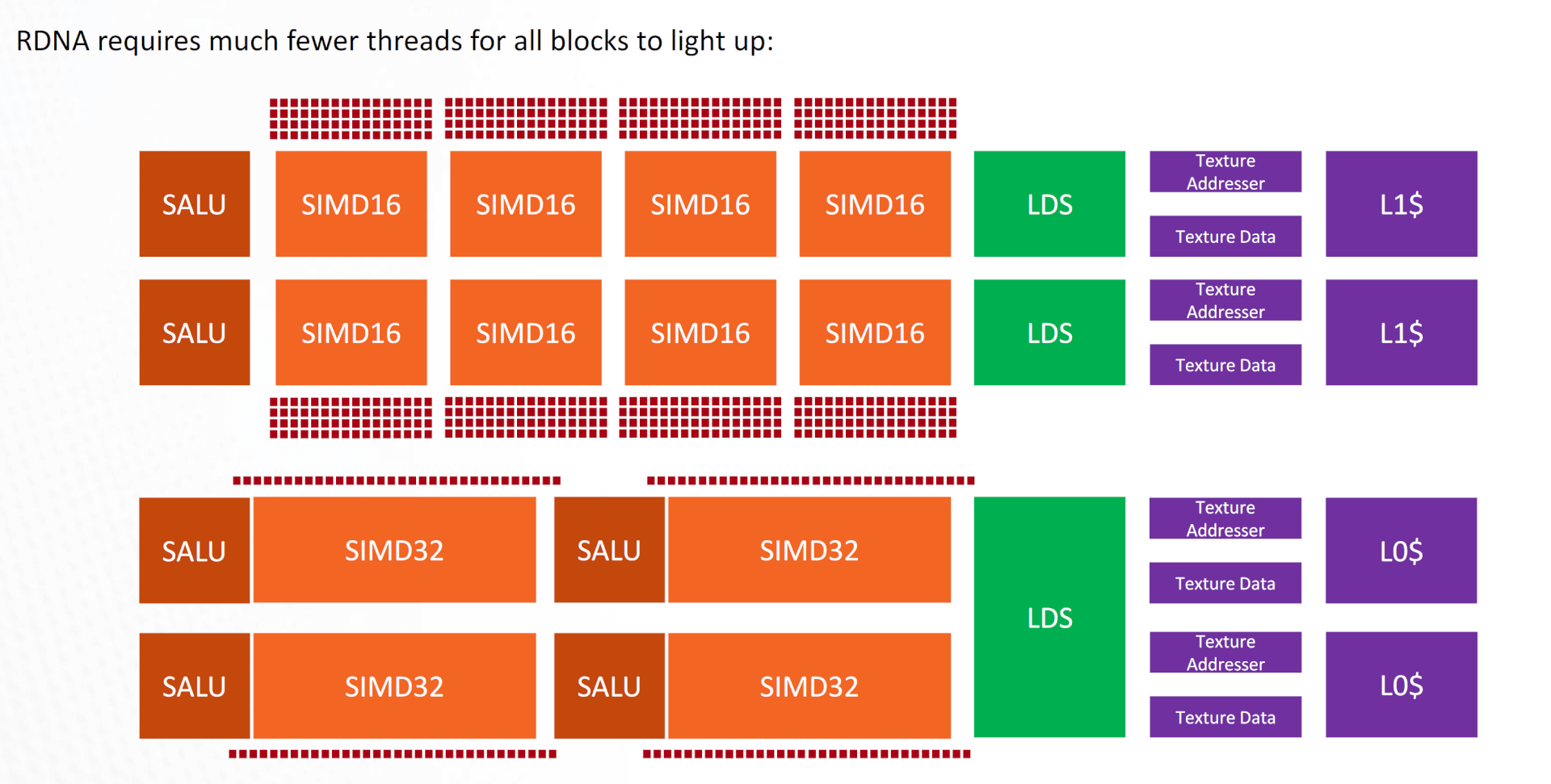
It’s much easier to saturate the SIMDs and thereby the WGPs on Navi (RDNA) compared to GCN. One WGP (2 CUs) requires just (4 SIMDs *32 items) 128 threads to reach 100% ALU utilization. GCN, on the other hand, needed (2 CUs * 4 SIMDs * 65 items) 512 threads to reach 100% utilization. That’s four times as much!
Video Encode and Decode
Like NVIDIA’s Turing encoder, the Navi GPUs also feature a specialized engine for video encoding and decoding.
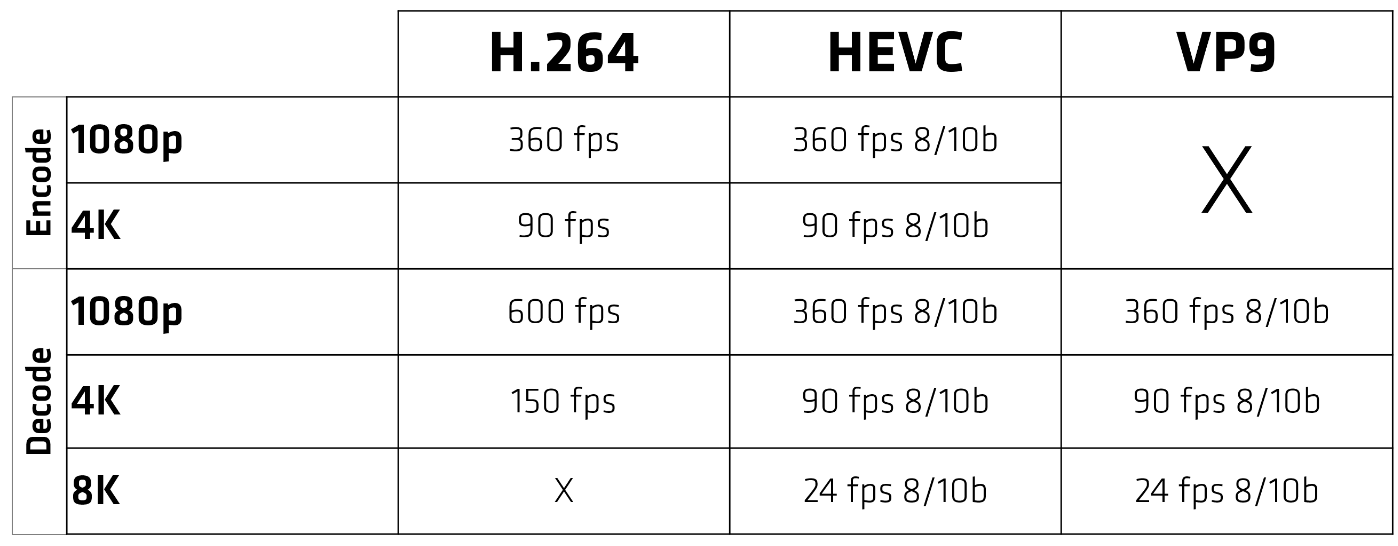
In Navi 10 (RX 5600 & 5700), unlike Vega, the video engine supports VP9 decoding. H.264 streams can be decoded at 600 frames/sec for 1080p and 4K at 150 fps. It can simultaneously encode at about half the speed: 1080p at 360 fps and 4K at 90 fps. 8K decode is available at 24 fps for both HVEC and VP9.
7nm Process and GDDR6 Memory Standard
While the 7nm node and GDDR6 memory are often advertised as part of the new architecture, these are third-party technologies and aren’t exactly part of the RDNA micro-architecture. The GPUs are, however, optimized to take maximum advantage of these technologies.
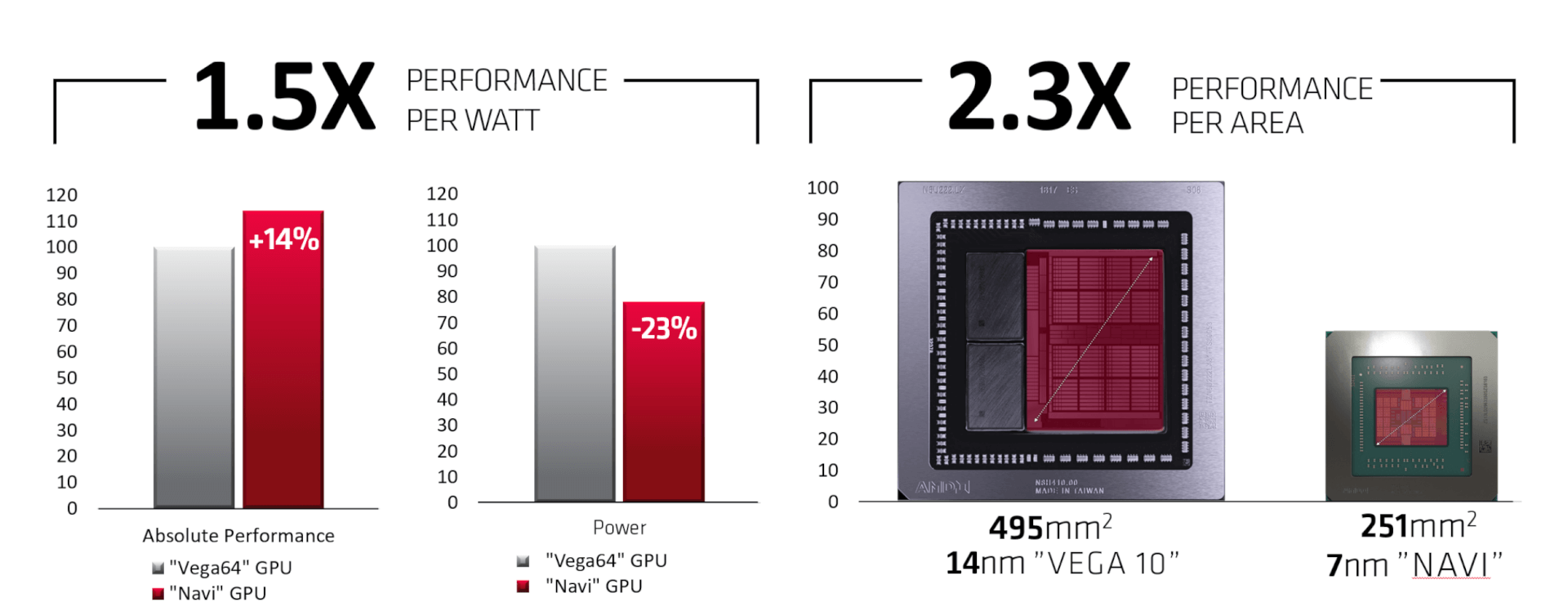
TSMC’s 7nm node does, however, improve the performance per watt significantly over the older 14nm process powering the older GCN designs, namely Polaris and Vega. It increases the performance per area by 2.3x and the performance per watt metric is boosted by 1.5x.
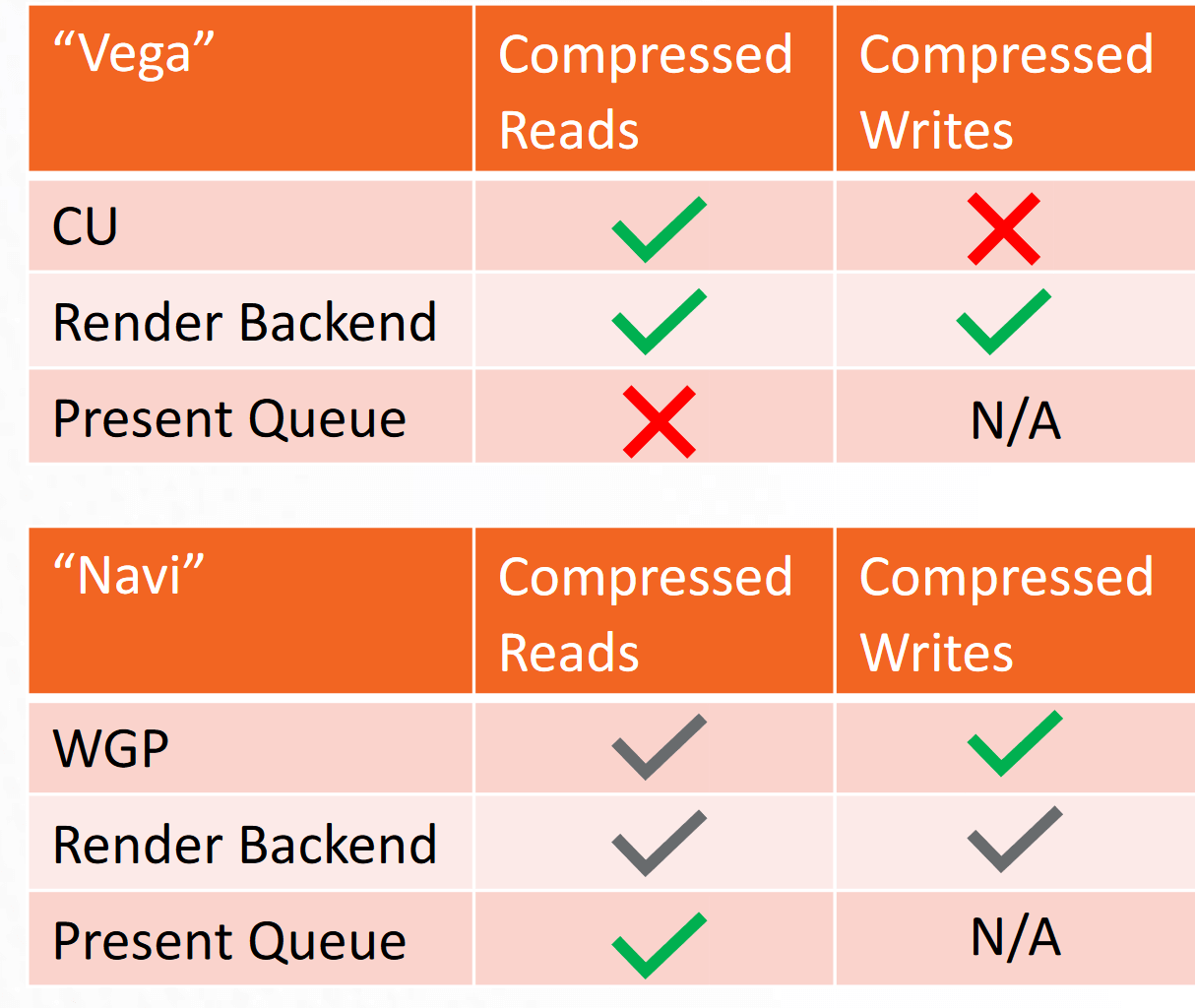
To maximize the bandwidth, data compression has been aggressively added wherever possible. While GCN and Navi did only compressed reads and writes in the RBs, Navi expands the latter to the CUs, in addition, to implementing it in the present queue as well.
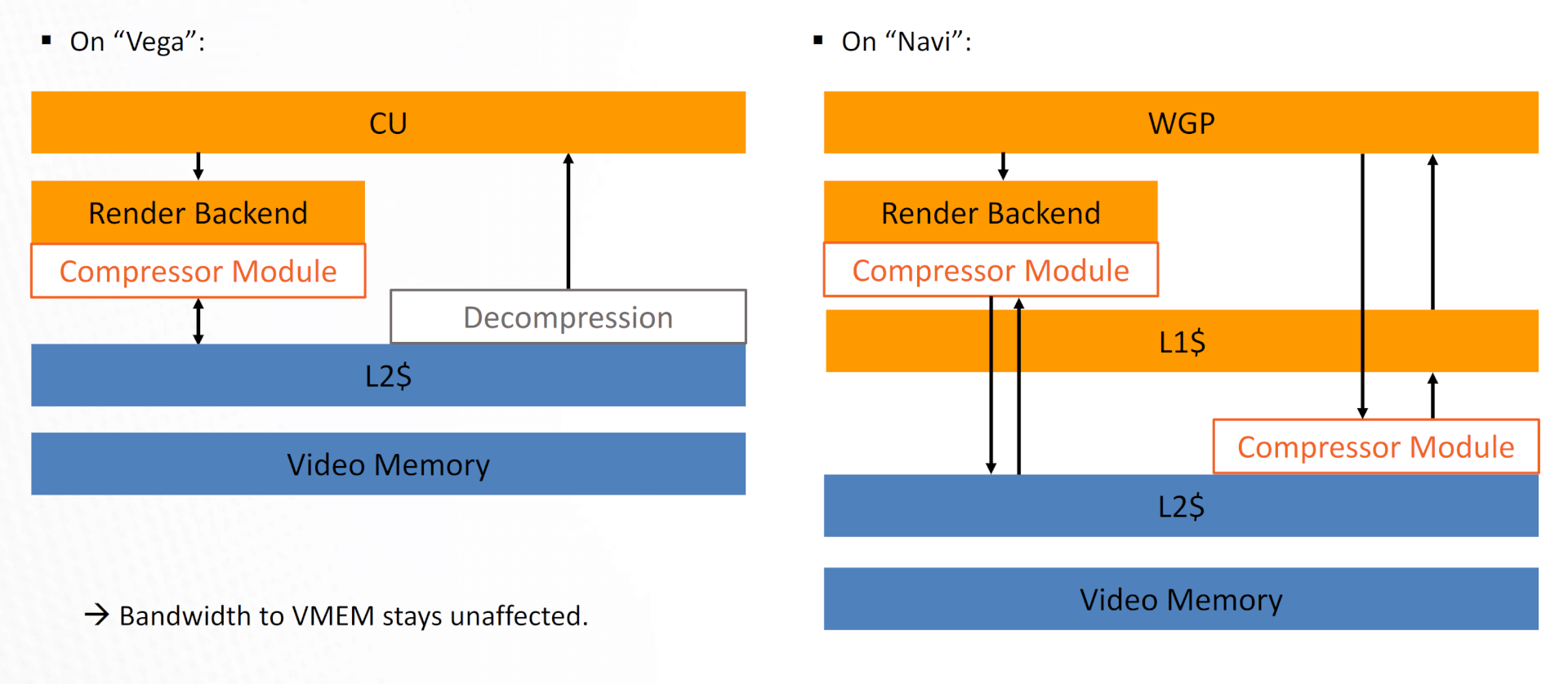
Now, there’s a compressor module between the WGP (CUs) and the L2 cache, in addition to the RBs. Vega was lacking the former, and data compression was limited to reads from the L2.
Conclusion
As you can see, while RDNA and Navi don’t exactly reinvent the Radeon design, they mainly just refine it. The pipeline bottlenecks have been removed, latency has been decreased and every SIMD is now wider and faster. There are more Render Backends per Shader Engine, with three levels of unified cache, a major step up from the preceding Vega GPUs. It’ll be interesting to see how different RDNA 2 will be from the existing Navi GPUs. To be honest, I don’t think there will be any radical changes. There might be some dedicated cores for ray-tracing acceleration or upscaling and that’s about it. What AMD needs to work on is their software and drivers.



