
AMD’s next-gen Ryzen 9000 processors are on track for launch in the second half of this year. By now, we know plenty about the Zen 5 core and the CPUs it’ll power. In this post, we’ll break down the specifications of the next-gen Ryzen 9000 series processors. First, we’ll review the expected release date, and then the specs and core architecture.

AMD Ryzen 9000 Series Release Date
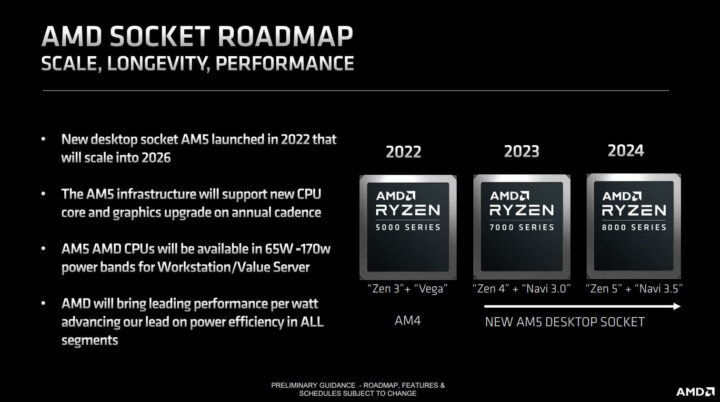
AMD has officially confirmed that its Zen 5 chips and the corresponding Ryzen 9000 processors will launch in the second half of 2024. This falls in line with what was reported last month. The chipmaker’s official roadmap says the same, there’s no reason to doubt it. But, when exactly in the second half of 2024 will the Ryzen 9000 series launch?
Looking back at AMD’s previous launches, the Ryzen 5000 CPUs were launched in October 2020, while the Ryzen 7000 series landed in September 2022. Both lineups were announced at the preceding Computex events, followed by a retail launch in the fall. Therefore, it would be fair to say that the Ryzen 9000 processors will be announced at Computex in June. The launch should take place between August and November. According to rumors, the Zen 5 chips are already in mass production.
AMD Ryzen 9000 “Granite Ridge” Specs
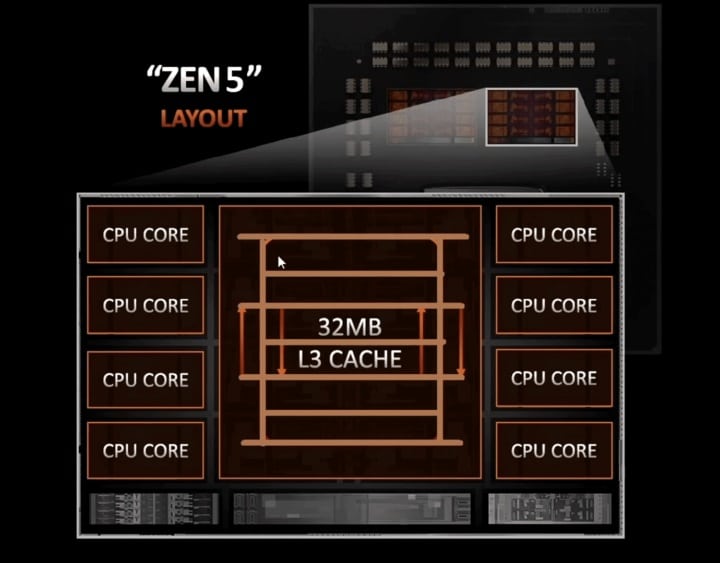
Every leak points to a 16-core flagship for the Ryzen 9000 desktop lineup consisting of two 8-core CCDs, each packing 32MB of unified L3 cache. The Zen 5 chips will be fabbed on TSMC’s 4nm process node. Here are the expected specifications of the Ryzen 9 9950X and Ryzen 7 9700X:
| Ryzen 9 9950X | Ryzen 7 9700X | |
|---|---|---|
| Cores/Threads | 16/32 | 8/16 |
| L2 Cache (per core) | 1MB | 1MB |
| L3 Cache (shared) | 64MB | 32MB |
| Boost Clock | 6GHz? | 6GHz? |
| PCIe Lanes (Gen 5) | 24? | 24? |
| Memory Support | DDR5-6000? | DDR5-6000? |
| TDP | 170W | 170W |
| PPT | 230W | 230W |
| Process | TSMC 4nm | TSMC 4nm |
| Launch | Q3 2024 | Q3 2024 |
The first Ryzen 9000 chip, an engineering sample, has been photographed (courtesy of @VallahExperte on X). We’re looking at an octa-core CPU, likely an early sample of the Ryzen 7 9700X.

The Zen 5 Core
Zen 5 Front End
The Zen 5 core architecture (codenamed Nirvana) will be a major upgrade over Zen 4, with a reworked frontend and a wider backend. Starting from the top, the L1D cache has been increased from 32KB to 48KB (12-way), complemented by an expanded Data Translation Buffer and a recalibrated branch predictor.
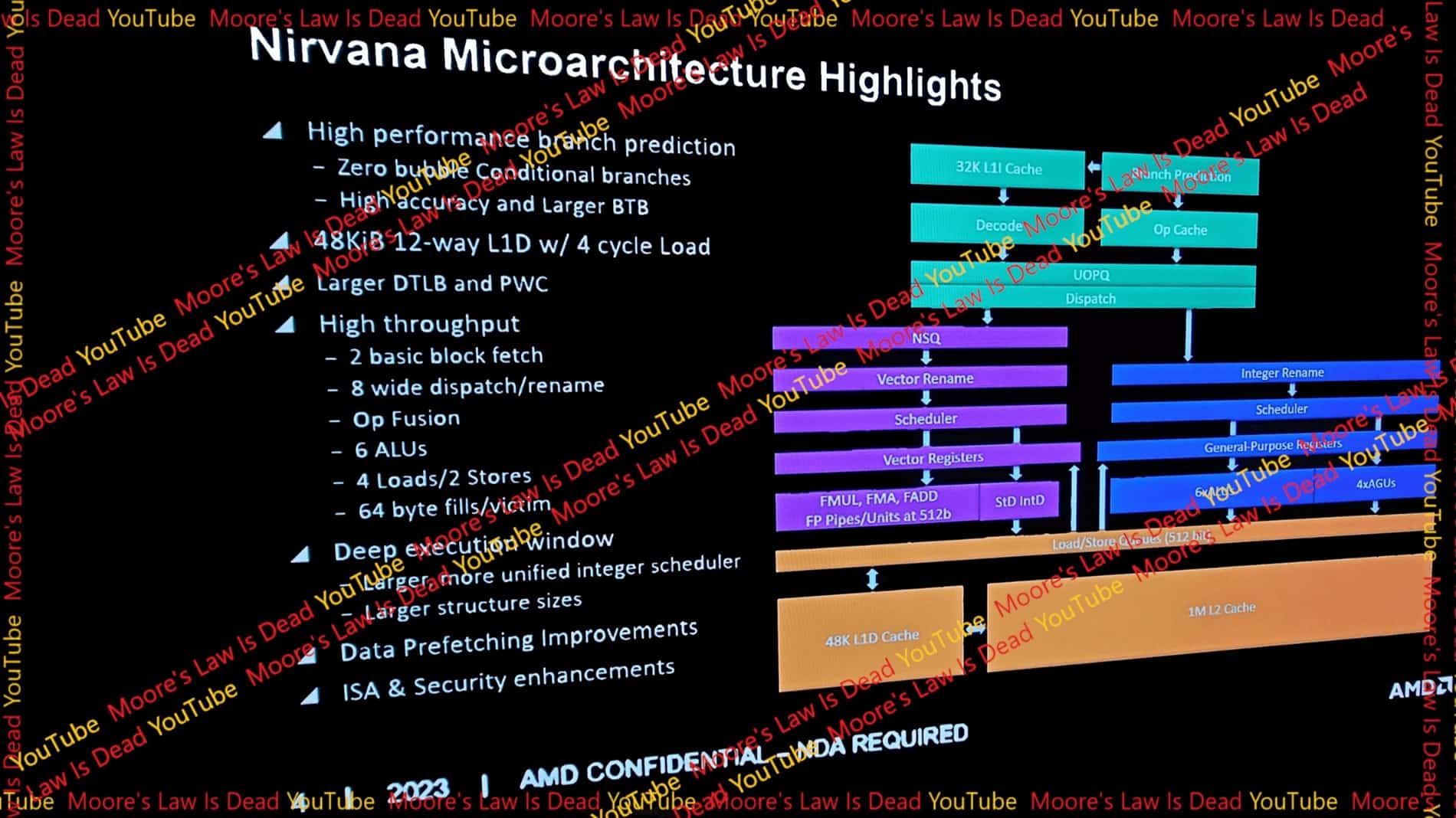
In out-of-order CPUs, the branch predictor is one of the most important components. Sitting at the top of the pipeline, it controls the instruction flow along with the Branch Target Buffer (BTB), which has also been upgraded. Zen 5’s branch predictor executes “Zero bubble” conditional branches. This implies that conditional branches are taken without interrupting or stalling the pipeline.
The decoder looks unchanged (4-way) with a 2-basic block fetch. The rename/dispatch buffer has been consolidated to simultaneously process up to 8 micro-ops (previously 6) with support for op-fusion. This allows two micro-ops from the same instruction to be treated as one at some points in the pipeline, doubling the effective throughput.
The Dispatch will also be upgraded from 6 maco-ops on Zen 4 to 8 macro-ops on Zen 5, keeping the backend fed at all times.
Zen 5 Backend
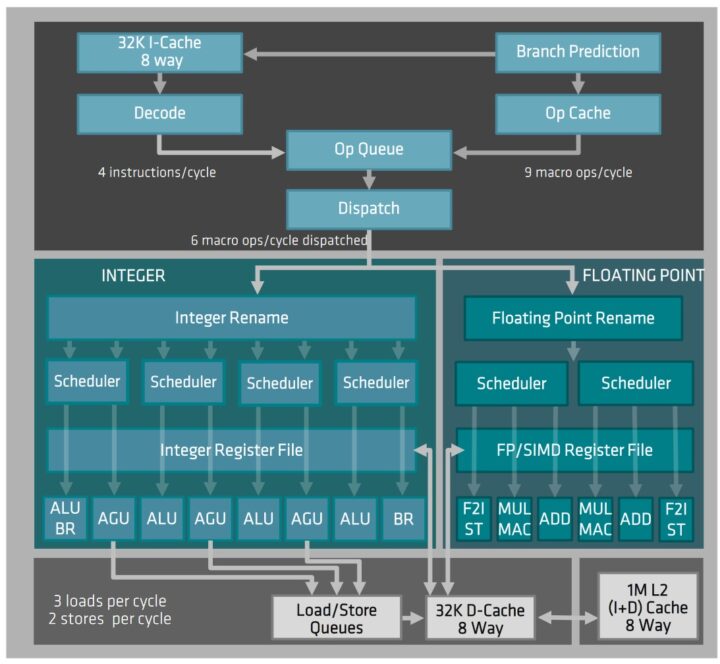
Zen 5 strengthens AMD’s already formidable Integer Execution. The integer scheduler has been reinforced into a unified queue with “larger structure sizes.” This means that multiple smaller scheduler windows have been consolidated into larger queues (4->2). The integer ALU count has been increased to 6 (previously 4) to accommodate the higher throughput.
A fourth AGU (Address Generation Unit) has also been added to keep the load-store queues fed. Overall, we’ve got 10 execution ports on Zen 5’s Integer backend. The Load/Store bandwidth has been expanded to 4 loads (previously 3) or two stores per cycle.

On the Floating Point end, all four execution ports have been doubled in width to 512-bit to support AVX-512 instructions. A fifth port consisting of two 256-bit units has also been added. The expanded EUs mean larger floating point registers to sustain them, substantially larger. For comparison, Intel designs only consist of one or two 512-bit units per core.
How do you think the following CPU-intensive games will run on the Core i9-15900K/Core Ultra 9? Here are our optimization guides:
Ladder L3 Fabric and Infinity Fabric Gen 3
AMD’s Ryzen 8000 processors will use an upgraded core interconnect known as the Ladder L3 Fabric (originally leaked by AdoredTV). This is related to the 3rd Gen Infinity Fabric, which will act as the die interconnects for AMD’s next generation of chiplet products. This bus impacts the core-to-core latency and bandwidth, which is crucial in gaming workloads. MLID claims that the fabric will be clocked at 2400MHz with a memory target of DDR5-8000 using EXPO.
AM5 800 Series Motherboards
AMD is working on an 800-series chipset for Zen 5 that will launch ahead of the Ryzen 9000 processors. The flagship X870E chipset will feature two Promontory 21 chips and an ASM4242 USB 4 controller. The inclusion of up to 20 PCIe 5 lanes (for dGPU and NVMe) will be the highlight. The B850 chipset will be the core of AMD’s next-gen budget offerings. It will sport PCIe Gen 5 support for at least the dGPU slot (x8 or x16?).
A B840 chipset based on Promontory 19 is also planned, but details remain sparse. AMD has set a memory target of DDR5-8000 for the Ryzen 9000 CPUs (with EXPO profiles), with an Fclk target of 2400MHz. The latter shouldn’t be an issue as the Ryzen 8000G processors are already designed for fabric clocks of 2400MHz and higher.
AMD Ryzen 9000X3D and Zen 5 V-Cache
According to Kepler, the Ryzen 9000X3D processors (Zen 5 3D V-Cache) will be revealed during CES 2025, slated to be held in the first week of January 2025. If the Ryzen 9000 “Zen 5” CPUs launch between summer and fall (June to September), then a 6-month gap separating them from the 3D V-Cache variants makes sense. This will depend on when Intel launches its 15th Gen Arrow Lake processors. They’ll have a similar effect on the market as Raptor Lake.
How do you think the Ryzen 9000 processors will perform compared to Intel’s Arrow Lake-S family? Will they offer superior gaming or content creation performance? And what about the NPUs? Which platform will be better at inferencing workloads?

