
In a new patent from AMD, researchers have highlighted techniques for performing machine learning operations using one or more dedicated ML accelerator chiplets. The resulting device is called an Accelerated Processing Device or APD which can be used for both gaming and data center GPUs via different implementations. The method involves configuring a part of the chiplet memory as cache while the other as directly accessible memory.
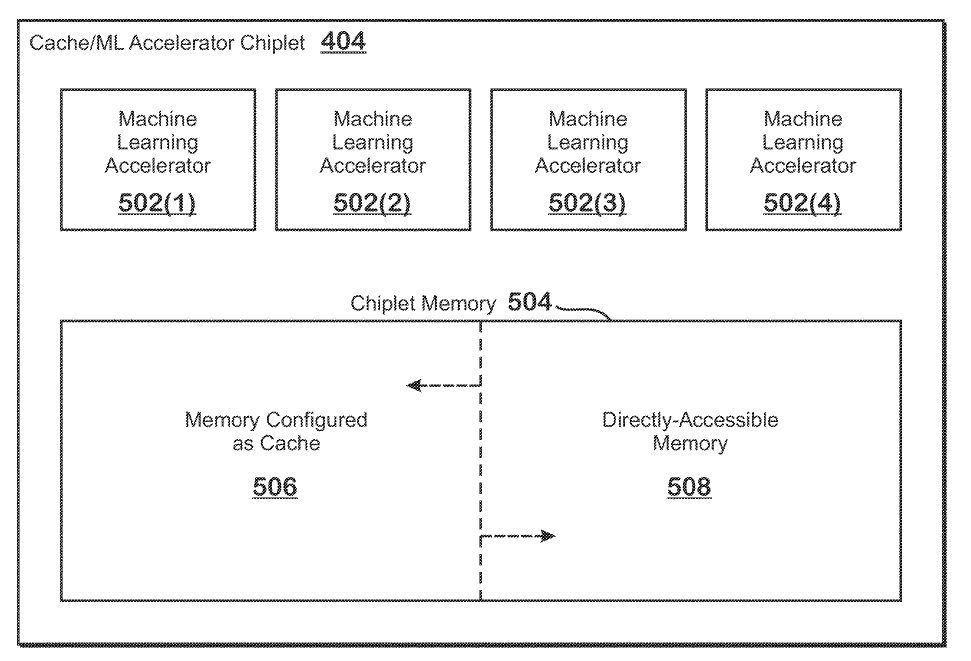
The sub-portion of the former is then used by the machine learning accelerators on the same chiplet to perform machine learning operations. The patent is very open-ended with respect to its uses, indicating possible use in CPUs, GPUs, or other caching devices, but the primary target appears to be GPUs with several thousand SIMD units.


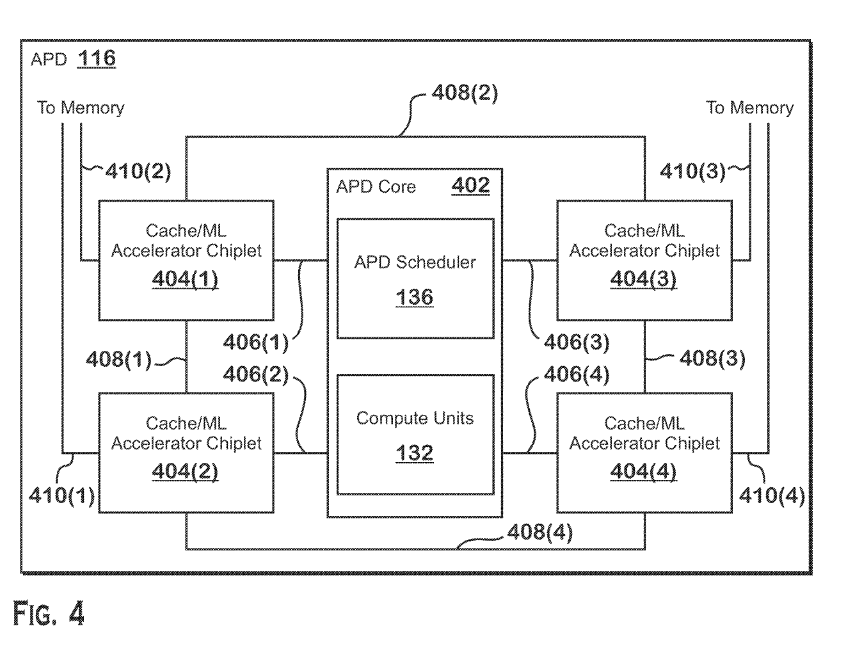
One implementation of the APD is configured to accept commands via both graphics and compute pipelines from the command processor, showing the ability to both render graphics as well as compute-intensive workloads required by convolution networks. The APD contains several SIMDs capable of performing vector operations alongside limited scalar and SP tasks similar to existing AMD GPUs.
Some implementations can include matrix multiplication circuits for Tensors, while other implementations can feature cache/machine learning accelerator chiplets on separate physical dies than the APD core fabricated using a more mature node than the core.
The memory on the ML chiplets can be switched between cache memory for the APD core or as cache/direct memory for storing the input and output results of the operations performed by the ML accelerators. There are options to allow part of the memory to be used as one and the rest as the other to vise versa.
Furthermore, the cache memory on the ML chiplets can also be used as the L3 cache for the APD (GPU) core, or as the physical interface between the APD core and the memory higher up (closer) to the GPU. Overall, the ML chiplet and its memory are highly configurable, allowing for diverse workloads.
CHIPLET-INTEGRATED MACHINE LEARNING ACCELERATORS – Advanced Micro Devices, Inc. (freepatentsonline.com)
